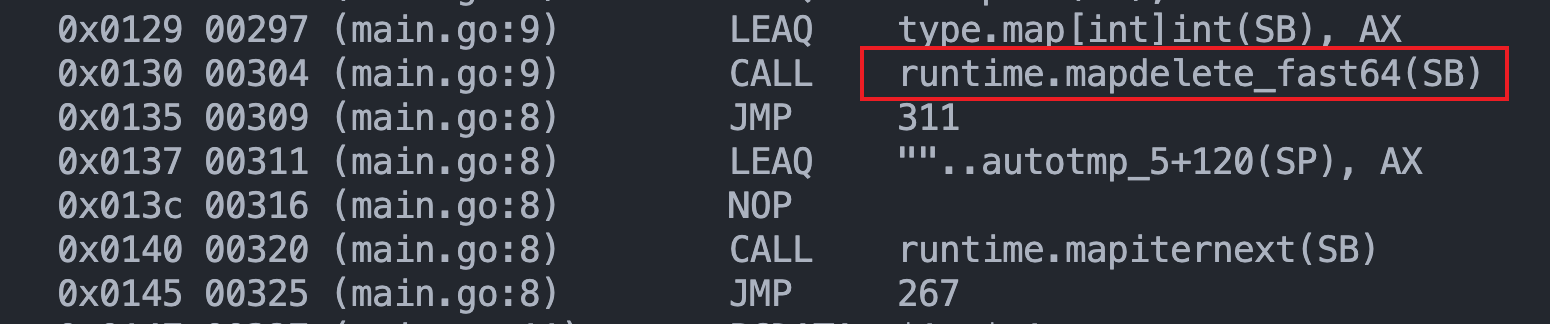
for i:=0 ;i< len(keys); i++ { mp[keys[i]] = values[i] }
makemap_small
1 2 3 4 5 6 7 8
// makemap_small implements Go map creation for make(map[k]v) and // make(map[k]v, hint) when hint is known to be at most bucketCnt // at compile time and the map needs to be allocated on the heap. funcmakemap_small() *hmap { h := new(hmap) h.hash0 = fastrand() return h }
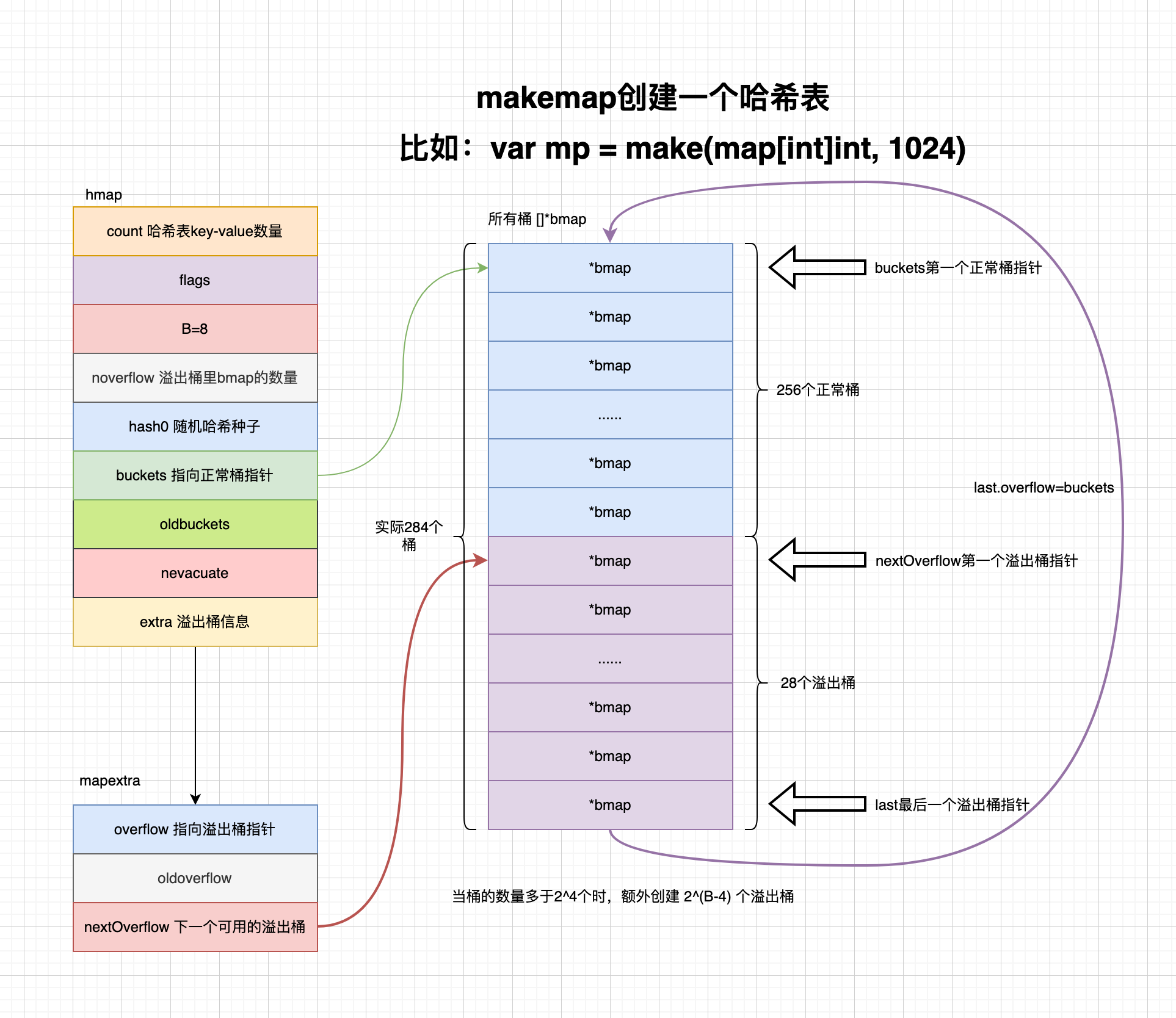
(dlv) b runtime.makemap Breakpoint 1 set at 0x40d4eafor runtime.makemap() /usr/local/go/src/runtime/map.go:303 (dlv) c > runtime.makemap() /usr/local/go/src/runtime/map.go:303 (hits goroutine(1):1 total:1) (PC: 0x40d4ea) Warning: debugging optimized function 298: // makemap implements Go map creation for make(map[k]v, hint). 299: // If the compiler has determined that the map or the first bucket 300: // can be created on the stack, h and/or bucket may be non-nil. 301: // If h != nil, the map can be created directly in h. 302: // If h.buckets != nil, bucket pointed to can be used as the first bucket. => 303: funcmakemap(t *maptype, hint int, h *hmap) *hmap { 304: mem, overflow := math.MulUintptr(uintptr(hint), t.bucket.size) 305: if overflow || mem > maxAlloc { 306: hint = 0 307: } 308: (dlv) p t.bucket.size 144 (dlv) p hint 1024 (dlv) p h *runtime.hmap nil ... > runtime.makemap() /usr/local/go/src/runtime/map.go:328 (PC: 0x40d588) Warning: debugging optimized function 323: // allocate initial hash table 324: // if B == 0, the buckets field is allocated lazily later (in mapassign) 325: // If hint is large zeroing this memory could take a while. 326: if h.B != 0 { 327: var nextOverflow *bmap => 328: h.buckets, nextOverflow = makeBucketArray(t, h.B, nil) 329: if nextOverflow != nil { 330: h.extra = new(mapextra) 331: h.extra.nextOverflow = nextOverflow 332: } 333: } (dlv) p h *runtime.hmap { count: 0, flags: 0, B: 8, noverflow: 0, hash0: 696655033, buckets: unsafe.Pointer(0x0), oldbuckets: unsafe.Pointer(0x0), nevacuate: 0, extra: *runtime.mapextra nil,} (dlv)
funcmapaccess1(t *maptype, h *hmap, key unsafe.Pointer)unsafe.Pointer { ...
// 访问的hmap为nil或者空map if h == nil || h.count == 0 { if t.hashMightPanic() { t.hasher(key, 0) // see issue 23734 } // 返回零值 return unsafe.Pointer(&zeroVal[0]) } // 标准map不允许并发读写 if h.flags&hashWriting != 0 { throw("concurrent map read and map write") } // 通过希函数hasher对key进行哈希映射,得到一个哈希值 hash := t.hasher(key, uintptr(h.hash0)) // 简单理解为 m=(1<<h.B)-1,获取桶数量 m := bucketMask(h.B)
// 通过hash后B位获取key映射到第几个桶 b := (*bmap)(add(h.buckets, (hash&m)*uintptr(t.bucketsize)))
// 下面这段代码有点东西。。。 if c := h.oldbuckets; c != nil { // 如果当前正在扩容,且是翻倍扩容,为了获得翻倍之前的旧桶数量 // 需要 m/2 获取旧桶数量 if !h.sameSizeGrow() { // There used to be half as many buckets; mask down one more power of two. m >>= 1 } // 第几个旧桶 oldb := (*bmap)(add(c, (hash&m)*uintptr(t.bucketsize))) // 如果该旧桶没有迁移完成,说明数据还保留着,没有被GC if !evacuated(oldb) { // 则访问该旧桶 b = oldb } }
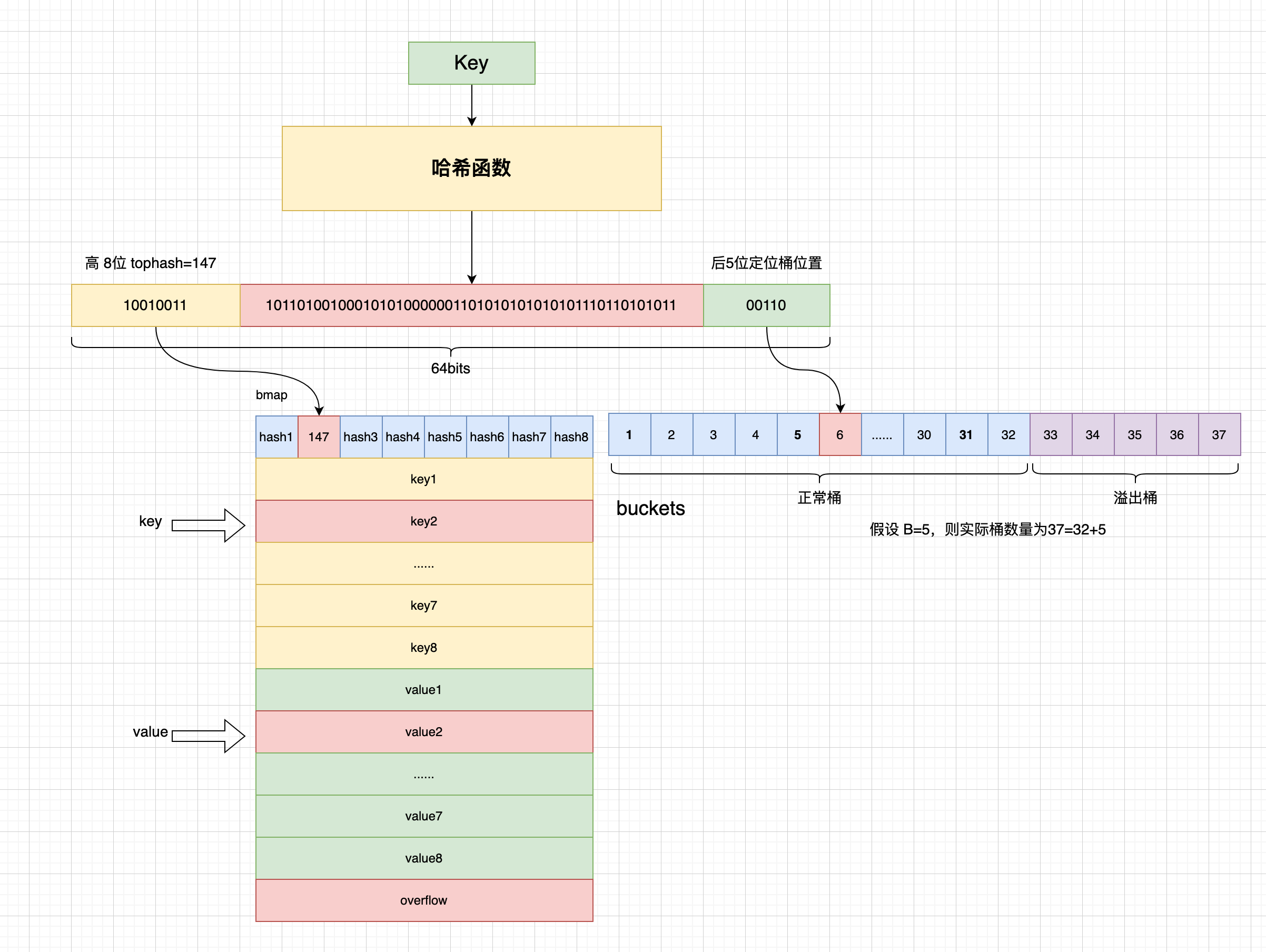
// 计算key哈希值的高8位 top := tophash(hash) bucketloop: // 遍历所有的bmap桶(包括正常桶和溢出桶) for ; b != nil; b = b.overflow(t) { // 遍历bmap桶中所有的tophash,一共8个tophash/key/value for i := uintptr(0); i < bucketCnt; i++ { // tophash不一致 if b.tophash[i] != top { // 当 tophash[0]=emptyRest 表示整个bucket都是空的 if b.tophash[i] == emptyRest { // 直接跳出循环遍历 break bucketloop } continue } // 获取keys的首地址,每个tophash对应一个key value k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize)) if t.indirectkey() { // 将 key 转换为 unsafe.Pointer 类型 k = *((*unsafe.Pointer)(k)) } // 判断存储在桶bmap.keys中的key 是否和访问的key相同 // 如果不相同,则跳过,继续判断下一个 tophash // 如果相同,则从桶bmap.elems 中获取对应的value if t.key.equal(key, k) { // 指针偏移获取对应的value e := add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.elemsize)) if t.indirectelem() { // 将value转换为 unsafe.Pointer 类型 e = *((*unsafe.Pointer)(e)) } // 返回vlaue指针 return e } } } // 不存在key,返回零值 return unsafe.Pointer(&zeroVal[0]) }
emptyRest = 0// 表示桶bucket是空 emptyOne = 1// 表示该bmap下的某个tophash是否为空,也就是可以插入 evacuatedX = 2// key/elem is valid. Entry has been evacuated to first half of larger table. evacuatedY = 3// same as above, but evacuated to second half of larger table. evacuatedEmpty = 4// cell is empty, bucket is evacuated. minTopHash = 5// minimum tophash for a normal filled cell.
functophash(hash uintptr)uint8 { // 32位: hash >> 24 // 64位: hash >> 56 top := uint8(hash >> (goarch.PtrSize*8 - 8)) // top < 5 ? if top < minTopHash { top += minTopHash } return top }
获取/设置当前 bmap 下一个溢出桶的首地址 *bmap,通过指针偏移获取和修改,为什么?
这是因为 Go 在编译期间动态确定bmap中的keys和elems,也就是键值类型,且最后一个字段保存着下一个溢出桶bmap的地址,即 overflow unsafe.Pointer(这也是为什么源码中bmap结构体只有tophash字段)。因此如果想要获取运行期间下一个bmap指针,只能通过指针偏移获取(梦回C语言🤔)。
funcmapaccess2(t *maptype, h *hmap, key unsafe.Pointer)(unsafe.Pointer, bool) { ... hash := t.hasher(key, uintptr(h.hash0)) m := bucketMask(h.B) b := (*bmap)(add(h.buckets, (hash&m)*uintptr(t.bucketsize))) ... top := tophash(hash) bucketloop: for ; b != nil; b = b.overflow(t) { for i := uintptr(0); i < bucketCnt; i++ { if b.tophash[i] != top { if b.tophash[i] == emptyRest { break bucketloop } continue } k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize)) if t.indirectkey() { k = *((*unsafe.Pointer)(k)) } if t.key.equal(key, k) { e := add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.elemsize)) if t.indirectelem() { e = *((*unsafe.Pointer)(e)) } // key存在,返回true return e, true } } } // key不存在,返回false return unsafe.Pointer(&zeroVal[0]), false }
mapaccessK
当通过语法 for k, v := range h {} 遍历map时,Go会在编译期间调用 mapaccessK 。遍历逻辑还是和mapaccess1一样,该函数返回两个指针,分别表示键和值的地址
funcmapaccessK(t *maptype, h *hmap, key unsafe.Pointer)(unsafe.Pointer, unsafe.Pointer) { ... hash := t.hasher(key, uintptr(h.hash0)) m := bucketMask(h.B) b := (*bmap)(add(h.buckets, (hash&m)*uintptr(t.bucketsize))) ... top := tophash(hash) bucketloop: for ; b != nil; b = b.overflow(t) { for i := uintptr(0); i < bucketCnt; i++ { if b.tophash[i] != top { if b.tophash[i] == emptyRest { break bucketloop } continue } k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize)) if t.indirectkey() { k = *((*unsafe.Pointer)(k)) } if t.key.equal(key, k) { e := add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.elemsize)) if t.indirectelem() { e = *((*unsafe.Pointer)(e)) } // 返回一个键值对指针 return k, e } } } returnnil, nil }
写入
总所周知,Go不能将key-value写入到一个nil的map中,否则报错 panic: assignment to entry in nil map,但是却可以读取一个nil的map。
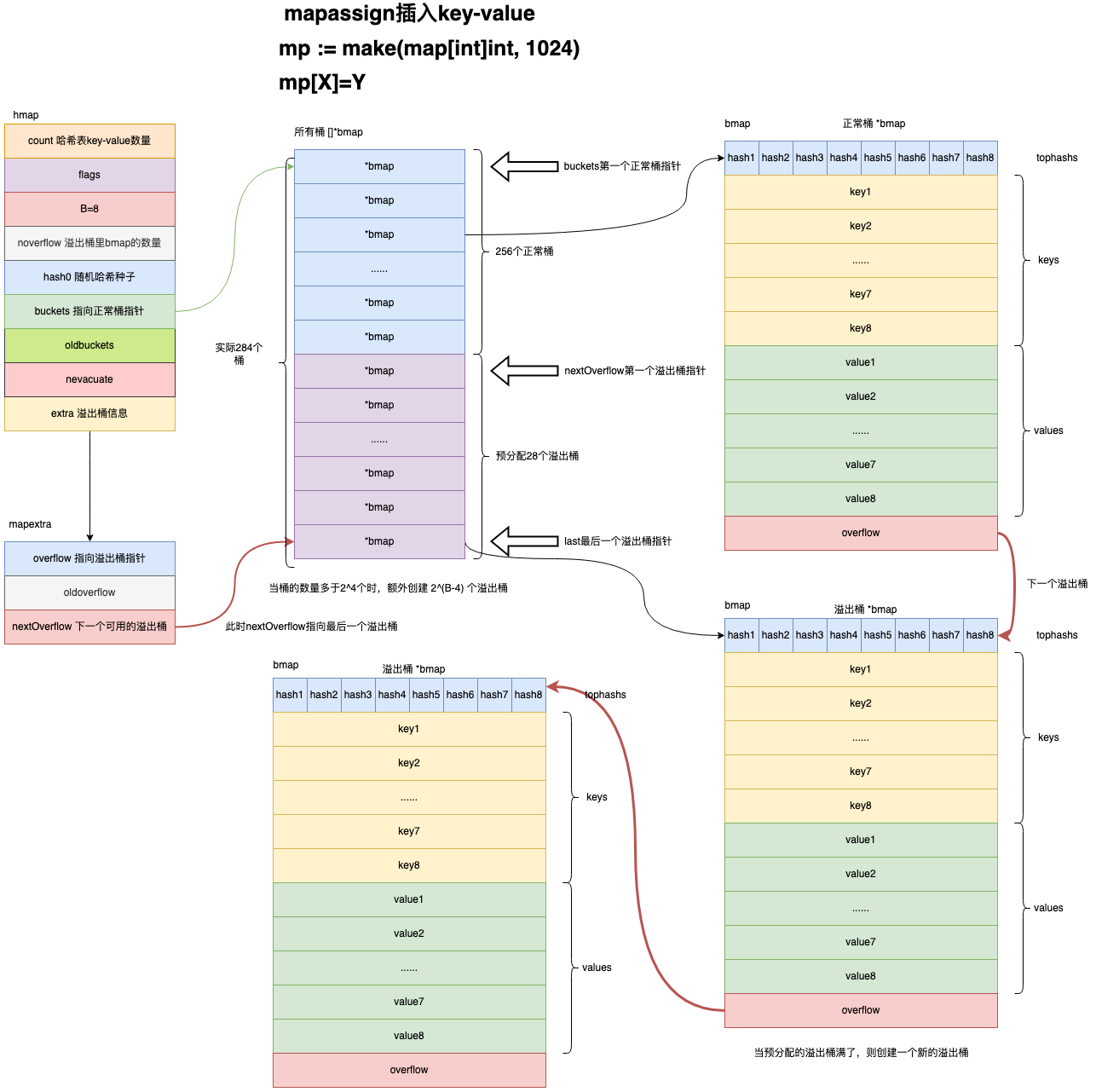
mapassign
Go通过 h[key] = value 对map添加键值,这是在编译期间将其转换为 mapassign 调用。
// 存放要修改的tophash、key、value引用 var inserti *uint8 var insertk unsafe.Pointer var elem unsafe.Pointer
// 遍历正常桶和所有溢出桶中的对应bmap bucketloop: for { // 遍历bmap的所有tophash/keys/values for i := uintptr(0); i < bucketCnt; i++ { if b.tophash[i] != top { // 该位置为空,可插入 if isEmpty(b.tophash[i]) && inserti == nil { inserti = &b.tophash[i] insertk = add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize)) elem = add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.elemsize)) } // 桶为空 if b.tophash[i] == emptyRest { break bucketloop } continue } // 获取该位置的key指针 k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize)) if t.indirectkey() { k = *((*unsafe.Pointer)(k)) } // key不相同则遍历下一个位置 if !t.key.equal(key, k) { continue } ... // 获取该位置的value指针 elem = add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.elemsize)) goto done } // 遍历下一个溢出桶 ovf := b.overflow(t) // 结束 if ovf == nil { break } b = ovf }
// 是否需要扩容 if !h.growing() && (overLoadFactor(h.count+1, h.B) || tooManyOverflowBuckets(h.noverflow, h.B)) { hashGrow(t, h) goto again // Growing the table invalidates everything, so try again }
// 判断是否处于扩容的状态 // If we hit the max load factor or we have too many overflow buckets, // and we're not already in the middle of growing, start growing. if !h.growing() && (overLoadFactor(h.count+1, h.B) || tooManyOverflowBuckets(h.noverflow, h.B)) { hashGrow(t, h) goto again // Growing the table invalidates everything, so try again }
functooManyOverflowBuckets(noverflow uint16, B uint8)bool { // If the threshold is too low, we do extraneous work. // If the threshold is too high, maps that grow and shrink can hold on to lots of unused memory. // "too many" means (approximately) as many overflow buckets as regular buckets. // See incrnoverflow for more details. if B > 15 { B = 15 } // The compiler doesn't see here that B < 16; mask B to generate shorter shift code. return noverflow >= uint16(1)<<(B&15) }
funchashGrow(t *maptype, h *hmap) { // If we've hit the load factor, get bigger. // Otherwise, there are too many overflow buckets, // so keep the same number of buckets and "grow" laterally. bigger := uint8(1)
// oldbucketmask provides a mask that can be applied to calculate n % noldbuckets(). func(h *hmap)oldbucketmask()uintptr { return h.noldbuckets() - 1 }
// 表示桶所有的槽位是否迁移完成,无论迁移前的槽位是否为空 funcevacuated(b *bmap)bool { h := b.tophash[0] return h > emptyOne && h < minTopHash }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
// 将旧桶数据分流到哪里 type evacDst struct { // 目标桶 b *bmap // key/value位于目标桶bmap哪一个槽位 i int // 新桶中key在内存中的地址 k unsafe.Pointer // 新桶中value在内存中的地址 e unsafe.Pointer }
// 偏移大小,可简单理解为获取bmap中keys起始地址,即跳过8字节的tophash const dataOffset = unsafe.Offsetof(struct { b bmap v int64// 8字节tophash }{}.v)
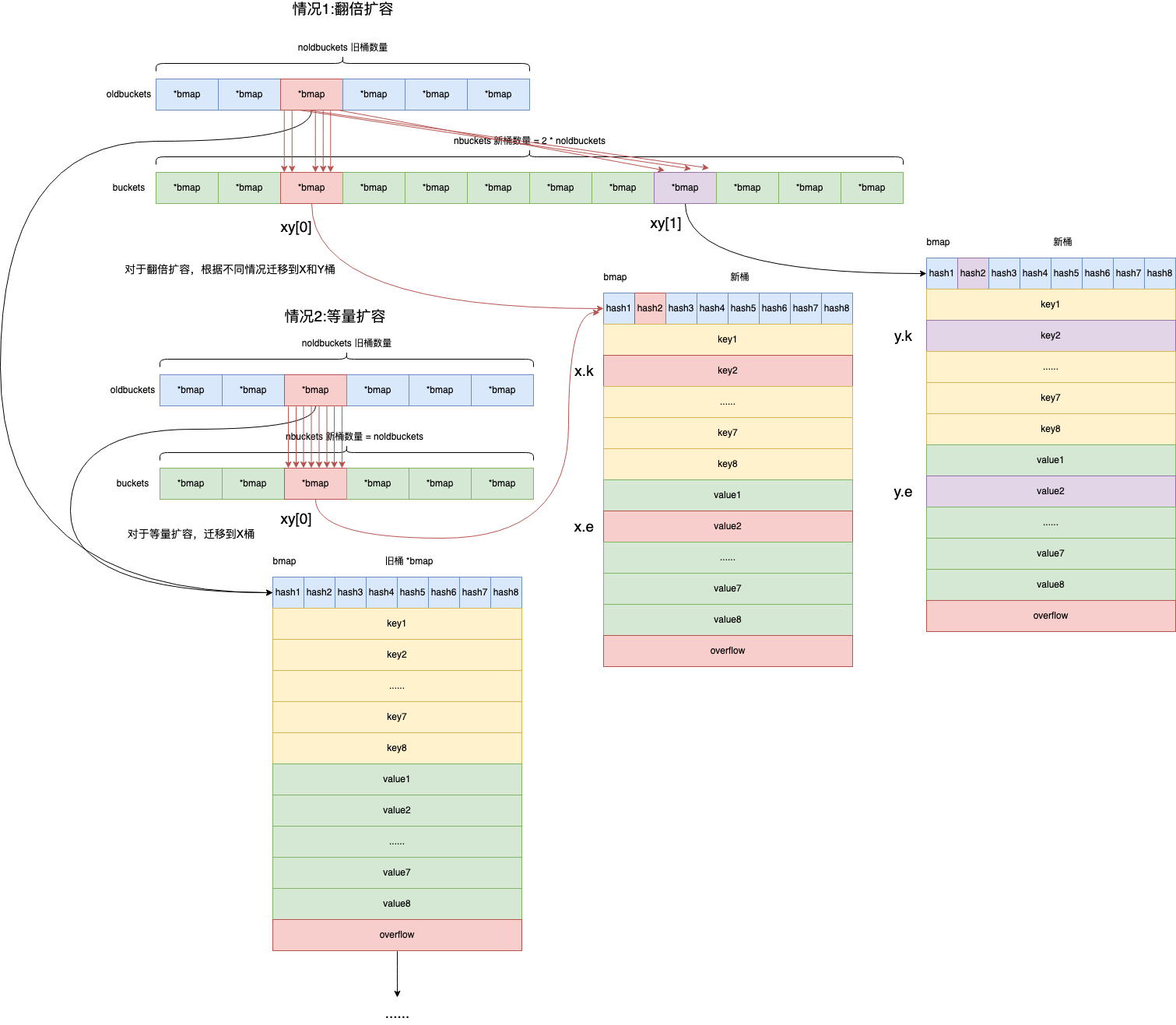
// bucket 表示需要迁移第几个旧桶 funcevacuate(t *maptype, h *hmap, oldbucket uintptr) { // 本次将要迁移的旧桶bmap b := (*bmap)(add(h.oldbuckets, oldbucket*uintptr(t.bucketsize))) // 旧桶数量 newbit := h.noldbuckets() // 旧桶是否已经迁移完成 if !evacuated(b) { // xy contains the x and y (low and high) evacuation destinations. var xy [2]evacDst x := &xy[0]
// 翻倍扩容 if !h.sameSizeGrow() { // Only calculate y pointers if we're growing bigger. // Otherwise GC can see bad pointers. y := &xy[1] // 数量翻倍后的新桶位置 y.b = (*bmap)(add(h.buckets, (oldbucket+newbit)*uintptr(t.bucketsize))) // 存放在新桶中的key内存地址 y.k = add(unsafe.Pointer(y.b), dataOffset) // 存放在新桶中的value内存地址 y.e = add(y.k, bucketCnt*uintptr(t.keysize)) }
// 遍历所有旧桶(正常桶和溢出桶),将每一个桶的key-value迁移到新桶 for ; b != nil; b = b.overflow(t) { // 获取旧桶bmap中keys内存起始地址 k := add(unsafe.Pointer(b), dataOffset) // 获取旧桶bmap中values内存起始地址 e := add(k, bucketCnt*uintptr(t.keysize)) // 遍历8个槽位,获取对应槽位上的 tophash-key-value for i := 0; i < bucketCnt; i, k, e = i+1, add(k, uintptr(t.keysize)), add(e, uintptr(t.elemsize)) { top := b.tophash[i] // 空槽位 if isEmpty(top) { // 标记该槽位迁移后为空,即没有key-value需要迁移 b.tophash[i] = evacuatedEmpty continue } if top < minTopHash { throw("bad map state") } // 获取key k2 := k if t.indirectkey() { k2 = *((*unsafe.Pointer)(k2)) } var useY uint8 // 翻倍扩容 if !h.sameSizeGrow() { // Compute hash to make our evacuation decision (whether we need // to send this key/elem to bucket x or bucket y). // 计算key哈希值,也就是key位于哪一个桶 hash := t.hasher(k2, uintptr(h.hash0)) if h.flags&iterator != 0 && !t.reflexivekey() && !t.key.equal(k2, k2) { // If key != key (NaNs), then the hash could be (and probably // will be) entirely different from the old hash. Moreover, // it isn't reproducible. Reproducibility is required in the // presence of iterators, as our evacuation decision must // match whatever decision the iterator made. // Fortunately, we have the freedom to send these keys either // way. Also, tophash is meaningless for these kinds of keys. // We let the low bit of tophash drive the evacuation decision. // We recompute a new random tophash for the next level so // these keys will get evenly distributed across all buckets // after multiple grows. // 当遇到math.NaN()的key时由tophash最低位决定迁移到X或者Y桶 // 因为使用math.Nan()作为key每次求hash都是不一样的。 useY = top & 1 // 重新计算tophash top = tophash(hash) } else { // 是否可以将数据存放在翻倍后的Y桶位置 if hash&newbit != 0 { useY = 1 } } }
funcadvanceEvacuationMark(h *hmap, t *maptype, newbit uintptr) { // 记录已经迁移完成的进度 h.nevacuate++ // Experiments suggest that 1024 is overkill by at least an order of magnitude. // Put it in there as a safeguard anyway, to ensure O(1) behavior. stop := h.nevacuate + 1024 if stop > newbit { stop = newbit } // bucketEvacuated 判断桶是否迁移完成 for h.nevacuate != stop && bucketEvacuated(t, h, h.nevacuate) { h.nevacuate++ } // 当所有的旧桶都迁移完成,则将oldbuckets和oldoverflow指针重置为nil if h.nevacuate == newbit { // newbit == # of oldbuckets // Growing is all done. Free old main bucket array. h.oldbuckets = nil // Can discard old overflow buckets as well. // If they are still referenced by an iterator, // then the iterator holds a pointers to the slice. if h.extra != nil { h.extra.oldoverflow = nil } h.flags &^= sameSizeGrow } }
type hiter struct { key unsafe.Pointer elem unsafe.Pointer t *maptype h *hmap buckets unsafe.Pointer // bucket ptr at hash_iter initialization time bptr *bmap // current bucket overflow *[]*bmap // keeps overflow buckets of hmap.buckets alive oldoverflow *[]*bmap // keeps overflow buckets of hmap.oldbuckets alive startBucket uintptr// bucket iteration started at offset uint8// intra-bucket offset to start from during iteration (should be big enough to hold bucketCnt-1) wrapped bool// already wrapped around from end of bucket array to beginning B uint8 i uint8 bucket uintptr checkBucket uintptr }
funcmapiterinit(t *maptype, h *hmap, it *hiter) { it.t = t if h == nil || h.count == 0 { return }
it.h = h
// grab snapshot of bucket state it.B = h.B it.buckets = h.buckets if t.bucket.ptrdata == 0 { h.createOverflow() it.overflow = h.extra.overflow it.oldoverflow = h.extra.oldoverflow }
// decide where to start r := uintptr(fastrand()) if h.B > 31-bucketCntBits { r += uintptr(fastrand()) << 31 } // 随机从某一个桶开始! it.startBucket = r & bucketMask(h.B) // 从该桶的随机一个槽位开始! it.offset = uint8(r >> h.B & (bucketCnt - 1)) // 指向桶指针 it.bucket = it.startBucket
// Remember we have an iterator. // Can run concurrently with another mapiterinit(). if old := h.flags; old&(iterator|oldIterator) != iterator|oldIterator { atomic.Or8(&h.flags, iterator|oldIterator) }