文本是对《Java 核心技术卷II》做的笔记,很早之前就写了,虽然本人已经转Go的😂,但是对有需要的同学可能有用。。。
Arrays.asList 返回可变的list,而List.of返回的是不可变的 list
Arrays.asList支持null,而List.of不行
List<Integer> list = Arrays.asList(1 , 2 , null ); 1 , 2 , null );
它们的contains方法对null处理不一样
List<Integer> list = Arrays.asList(1 , 2 , null ); 1 , 2 , null );
Arrays.asList:数组的修改会影响原数组
Integer[] array = {1 ,2 ,3 };1 ] = 10 ;1 ,2 ,3 };1 ] = 10 ;
注意 Arrays.asList() 实际上是
public static <T> List<T> asList (T... a) {return new ArrayList<>(a);
其中的 new ArrayList<>(a) 类 ArrayList实际上是 Arrays 的 静态内部类,并不是集合 ArrayList!!!。
也就是
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 public class Arrays private static class ArrayList <E > extends AbstractList <E > implements RandomAccess , java .io .Serializable {@SuppressWarnings("serial") private final E[] a;@Override public int size () return a.length;
而标准的集合 ArrayList 是 List 的子类,实现于 Collection,是真正意义上的泛型列表,支持更多的操作。
支持将一个 合集 传递给构造函数,并不支持直接传递一个 数组
public ArrayList (Collection<? extends E> c)
流并不存储其元素
流的操作不会修改其数据源
流的操作是尽可能惰性执行的
用 Collection 接口的 stream 方法将任何 集合 转换为一个 流 。或者通过 Stream.of/Arrays.stream 将 数组 转换为 流 。
空流:Stream.empty()
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 package com.test3;import java.util.ArrayList;import java.util.List;import java.util.Random;public class Test5 public static void main (String[] args) new ArrayList<>();new Random();for (int i = 0 ; i < 100 ; i++) {10000 ));long count = list.stream().filter(v -> v > 5000 ).count();
创建 无限流 方法
Stream.generate(Supplier<T>):比如 Stream.generate(Math::random)Stream.iterate(T seed, UnaryOperator<T>) 无限序列:Stream.iterate(BigInteger.ZERO, n -> n.add(BigInteger.ONE))
Stream<BigInteger> stream = Stream.iterate(BigInteger.ZERO, n -> n.add(BigInteger.ONE));5 ).forEach(v -> System.out.println(v));
filter 过滤。产生一个流,它包含当前流中所有满足断言条件的元素map 变换。会有一个函数应用到每个元素上,并且其结果是包含了应用该函数后所产生的所有结果的流flatMap 。将 mapper 应用于当前流中所有元素所产生的结果连接到一起而获得的
String[] arr = {"hello" , "world" , "linux" };
Stream.limit 裁剪无限流的尺寸Stream.skip 它会丢弃前 n 个元素Stream.concat 将两个流连接起来
Stream.distinct 删除重复的元素Stream.sorted 排序流中的元素Stream.peek 它的元素与原来流中的元素相同,但是在 每次获取一个元素时,都会调用一个函数
Stream.of("hello" , "world" , "hello" , "hello" , "xx" ).distinct().forEach(System.out::println);100 , 20 , 5 , 1000 , 4023 ).sorted(Comparator.reverseOrder()).forEach(System.out::println);"hello" , "world" ).peek(v -> System.out.print("-> " )).forEach(System.out::println);
约简是一种终结操作,它们会将流约简为可以在程序中使用的 非流值 (比如 int, long…)
Optional<T> 对象是一种 包装器对象 ,要么包装了类型 T 的对象 , 要么没有包装任何对象 。
对于第一种情况,我们称这种值为存在的 。Optional<T> 类型被当作一种更安全的方式,用来替代类型 T 的引用 ,这种引用要么引用某个对象,要么为 null。类似 C++ std::optional<T>
建议查看 Optional 类代码
Optional<Integer> optInt = Optional.of(200 );new Random().nextInt(1000 )));
在 并行流上,forEach 方法会以任意顺序 遍历各个元素,如果想要按照流中的顺序来处理它们,可以调用 forEachOrdered 方法
Stream.forEachStream.toArray(XXX[]::new) 返回 Object[]。收集到 数组 Stream.collect(Collectors.toXXX()) ,收集到 集合 Collector Collectors 类提供 了大量用于生成公共收集器的工厂方法IntSummaryStatistics|DoubleSummaryStatistics|LongSummaryStatistics 将 mapper 应用于每个元素后所产生的结果的个数、总和、平均值、最大值和最小值。
String[] strings = Stream.of("100" , "hello" ).toArray(String[]::new );"100" , "hello" , "hello" , "world" ).collect(Collectors.toSet());10 , 20 , 30 ).collect(Collectors.toCollection(TreeSet::new ));"hello" , "world" ).collect(Collectors.joining("|" ))10 , 20 , 30 ).collect(Collectors.summarizingInt(x -> x * x)).getSum());
Collectors.toMap产生映射表的键和值
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 package com.test3;import java.util.Map;import java.util.stream.Collectors;import java.util.stream.Stream;public class Test6 private static class Person private int id;private String name;public Person (int id, String name) this .id = id;this .name = name;public int getId () return id;public int getMapId (int factor) return factor * id;public String getName () return name;public static void main (String[] args) new Person(100 , "mike" ),new Person(200 , "tony" ),new Person(300 , "john" ));100 ), Person::getName)
groupingBygroupingByConcurrentpartitioningBy
groupingBy 原型如下,可以看到传递一个 Function<T,K> 的分类器,然后返回 Map<K,List<T>> 的 映射对象,其中映射的键类型就是分类器返回的类型 K
public static <T, K> Collector<T, ?, Map<K, List<T>>> super T, ? extends K> classifier) {return groupingBy(classifier, toList());
public static void main (String[] args) new Person(100 , "mike" ),new Person(200 , "tony" ),new Person(300 , "john" ));200 )false =[com.test3.Test6$Person@30f39991], true =[com.test3.Test6$Person@452b3a41, com.test3.Test6$Person@4a574795]}
groupingBy 方法会产生一个 映射表 ,它的每个值都是一个列表 。 如果想要以某种方式来处理这些列表,就需要提供 一个“下游收集器”。默认情况下是 toList() 也就是下游收集器得到的是一个列表。
": " + v.toString());200 , name='tony' }]100 , name='mike' }]300 , name='john' }]
Java 提供了多种可以将 群组元素 约简为 数字 的收集器:
counting 会产生收集到的元素的个数summing(Int|Long|Double) 会接受 一个函数作为引元,将该函数应用到下游元素中,并产生它们的和maxBy 和 minBy 会接受一个比较器,并产生下游元素中的最大值和最小值mapping 方法会产生将函数应用到下游结果上的收集器,将 函数值 传递给另 一个收集
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 public static void main (String[] args) new Person(100 , "mike" ),new Person(200 , "tony" ),new Person(400 , "mike" ),new Person(300 , "john" ));": " + v.toString());1 2 1
T reduce(T , BinaryOperator<T> );Optional<T> reduce(BinaryOperator<T> );<U> U reduce(U ,BiFunction<U, ? super T, U> accumulator,BinaryOperator<U> combiner);
reduce 方法是一种用于 从流中计算某个值 的通用机制,其最简单的形式将接受一个二元函数,并从前两个元素开始持续应用它。
通常,如果 reduce 方法有一项约简操作 op,那么可以表示为 (((v0 op v1) op v2) ...)
其中的 op(vi, vj) 函数写作 vi op vj。可以用于 求和、乘积、字符串连接、取最大值和最小值 、 求集的并与交等
初值的类型用于决定应该返回什么类型的值!
Integer sum = list.stream().reduce(0 , (x, y) -> x + y);"android" , "macos" , "linux" , "windows" );int len = strings.stream().reduce(0 , (t, s) -> t + s.length(), Integer::sum);
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 1. T reduce (T identity, BinaryOperator<T> accumulator) ;for (T element : this stream)return result;2. Optional<T> reduce (BinaryOperator<T> accumulator) ;boolean foundAny = false ;null ;for (T element : this stream) {if (!foundAny) {true ;else return foundAny ? Optional.of(result) : Optional.empty();3. <U> U reduce (U identity, BiFunction<U, ? super T, U> accumulator, BinaryOperator<U> combiner) U result = identity;for (T element : this stream)return result;
直接存储基本类型值,而无需使用包装器
为了 创建 IntStream ,需要调用 IntStream.of(int... ) 和 Arrays.stream 方法。
IntStream 和 Long Stream 有静态方法 range 和 rangeClosed ,可以生成步长为 1 的整数范围
为了将基本类型流转换为对象流,需要使用 boxed 方法
IntStream stream = IntStream.of(100 , 200 , 300 );
Random 类具有 ints 、 longs 和 doubles 方法,它们会返回由随机数构成的 基本类型流
从任何集合 中获取一个并行流 Collection.parallelStream
将任意的顺序流 转换为并行流 Stream.parallel
只要在终结方法执行时,流处于并行模式,那么 所有的中间流操作 都将被井行化。
当流操作并行运行时,其目标是要让其返回结果与顺序执行时返回的结果相同。重要的是,这些操作可以以任意顺序执行。要确保传递给并行流操作的任何函数都可以安全地并行执行
不要修改在执行某项流操作后会将元素返回到流中的集合,流并不会收集它们的数据,数据总是在单独的集合中 。 如果修改了这样的集合,那么流操作的结果就是未定义的。
void mark(int readlimit) 在输入流的当前位置打一个标记(并非所有的流都支持这个特性) 。 如果从输入流中已经读人的字节多于 readlimit 个,则这个流允许忽略这个标记void reset() 返回到最后一个标记,随后对 read 的调用将重新读入这些字节。如果当前没有任何标记,则这个流不被重置
FileInputStream/FileOutputStream
BufferedInputStream/BufferedOutputStream
PushbackInputStream
在存储文本字符串时,需要考虑字符编码( character encoding )方式。在 Java 内部使用的 UTF-16 编码方式中
DataInputStreamDataOutputStreamRandomAccessFile 随机访问文件
ZipInputStreamZipOutputStreamZipEntryZipFile
ZipInputStream zipInputStream = new ZipInputStream(new FileInputStream("basic/libs/mysql-connector-java-8.0.26.jar" ));for (ZipEntry entry; ((entry = zipInputStream.getNextEntry()) != null ); ) {
对象实现 Serializable 接口
ObjectOutputStreamObjectInputStream
每个对象都是用一个 序列号(serial number) 保存的,这就是这种机制之所以称为对象序列化的原因
PathFileStandardOpenOptionStandardCopyOptionBasicFileAttributesPosixFileeAttributesDosFileAttributes
DirectoryStream 是 Iterable 的子接口,一种常见的用法是用 for 循环来遍历目录,支持 glob 模式
注意,遍历不是递归的。
public static void main (String[] args) throws IOException "./basic/src" ), "*.java" );for (Path path : ds) {
如果想要访问 某个目录的所有子孙成员 ,可以转而调用 walkFileTree 方法,并向其传递一个 FileVisitor 类型的对象
在遇到一个文件或目录 时: FileVisitResult visitFile(T path , BasicFileAttributes attrs)
在一个目录被处理前:FileVisitResult preVisitDirectory(T dir , IOException ex)
在一个目录被处理后:FileVisitResult postVisitDirectory(T dir , IOException ex)
在试图访问文件或目录时 发生错误 :FileVisitResult visitFileFailed(path, IOException)。此时可以:
继续访问下一个文件:FileVisitResult.CONTINUE
继续访问,但是不再访问这个目录下的任何项:FileVisitResult.SKIP_SIBLINGS
继续访问,但是不再访问这个文件的兄弟目录(和该文件在同一个目录下的文件): FileVisitResult.TERMINATE
便捷类 SimpleFileVisitor 实现了 FileVisitar 接口,可以实现递归访问某个父目录下的所有子目录和文件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 Files.walkFileTree(Paths.get("." ), new SimpleFileVisitor<>() {@Override public FileVisitResult preVisitDirectory (Path dir, BasicFileAttributes attrs) throws IOException return FileVisitResult.CONTINUE;@Override public FileVisitResult visitFileFailed (Path file, IOException exc) throws IOException return FileVisitResult.SKIP_SUBTREE;@Override public FileVisitResult postVisitDirectory (Path dir, IOException exc) throws IOException return FileVisitResult.CONTINUE;
NIO.2 的 Path 类提供了如下 一 个方法来监听文件系统的变化
WatchService 代表 一 个文件系统监听服务,它负责监昕 path 代表的目录下的 文件变化 。
poll()获取下 一 个 WatchKey ,如果没有 WatchKey 发生就立即返回 nullpoll(long timeout , TimeUnit unit) 尝试等待 timeout 时间去 获取下 一 个 WatchKeytake() 获取下 一 个 WatchKey ,如果没有 WatchKey 发生就一直等待ENTRY_CREATE 创建ENTRY_MODIFY 修改,包括修改权限之类的ENTRY_DELETE 删除
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 package com.test6;import java.nio.file.*;public class PathWatchService public static void main (String[] args) throws Exception "/home/joxrays/Desktop/" ).register(watchService,while (true ) {for (WatchEvent<?> event : key.pollEvents()) {"\t" + event.kind());boolean reset = key.reset();if (!reset) {break ;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 package com.test4;import java.io.IOException;import java.nio.file.*;import java.nio.file.attribute.BasicFileAttributes;public class Test3 public static void main (String[] args) throws IOException "basic/libs/mysql-connector-java-8.0.26.jar" ));"/" ), new SimpleFileVisitor<>() {@Override public FileVisitResult visitFile (Path file, BasicFileAttributes attrs) throws IOException return FileVisitResult.CONTINUE;
首先,从文件中获得一个 通道(channel) ,确切来说应该是 文件通道 FileChannel,通道是用于磁盘文件的一种抽象,它使我们可以访问诸如内存映射、文件加锁机制以及文件间快速数据传递等操作系统特性。FileChannel.open()
所有的 Channe l 都不应该通过构 造器来直接 创 建,而是通过传统的节点 InputStream 、 OutputStream的 getChannel 方法来返回对应的 Channel ,不同的节点流获得的 Channel 不 一 样。
文件通道 总是阻塞的,因此不能被置于非阻塞模式
映射模式 FileChannel.MapMode
只读 read-only
读写 read-write
私有 private
一旦有了缓冲区,就可以使用 ByteBuffer 类和 Buffer 超类的方法读写数据。Java 对二进制数据使用 高位在前 的排序机制(大端模式)。
可以修改为小端模式
buffer.order(ByteOrder.LITTLE_ENDIAN);
getputMappedByteBuffer map(MapMode mode, long position, long size) 将文件的一个区域映射到内存中static ByteBuffer allocate(int capacity) 构建具有给定容量的缓冲区static ByteBuffer wrap(byte[] values) 构建具有指定容量的缓冲区,该缓冲区是对给定数组的包装 CharBuffer asCharBuffer() 构建字符缓冲区,它是对当前这个缓冲区的包装transferFromtransferTo
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 package com.test4;import java.io.IOException;import java.nio.ByteBuffer;import java.nio.channels.FileChannel;import java.nio.file.Files;import java.nio.file.Path;import java.nio.file.StandardOpenOption;public class MMapTest public static void main (String[] args) throws IOException "basic/res/LICENSE" );long size = Files.size(path);"File size: " + size);0 , size);"position: " + buffer.position());"limit: " + buffer.limit());byte [] bytes = new byte [(int ) size];"position: " + buffer.position());
transferTo 例子,这里实现了快速拷贝一个文件到另一个文件。
public static void main (String[] args) throws IOException new RandomAccessFile("basic/res/web.html" , "rw" );new RandomAccessFile("basic/res/web2.html" , "rw" );long position = 0 ;long count = fromChannel.size();
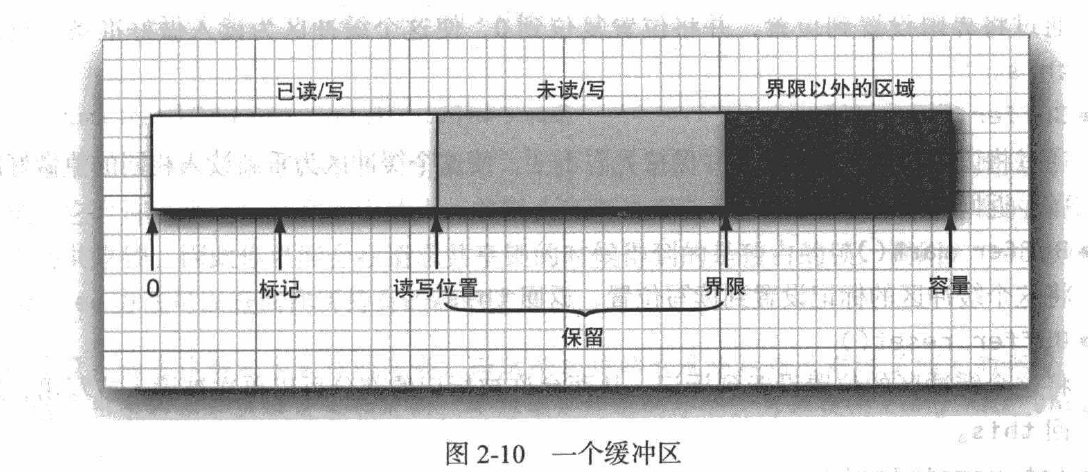
每个缓冲区都有一下特征:
一个不能改变容量
一个读写位置
一个界限
一个可选的标记
在 Buffer 中有 三 个重要的概念:容量 C capacity )、界限 C limit ) 和位置 C position ) 。
容量 (capacity ) : 缓冲区的容量 C capacity) 表示该 Buffer 的最大数据容 量 ,即最多可以存储多少数据 。 缓冲区的容量不可能为负值, 创 建后不能改变 。
界限( limit ): 第 一 个不应该被读出或者写入的缓冲区位置索引 。 也就是说,位于 limit 后的数据既不可被读,也不可被写 。
位置 ( position ) : 用 于 指明 下 一 个可以被读出的或者写入的缓冲区位置索引(类似于 10 流中的记录指针 )。当 使用 Buffer 从 Channel 中 读取数据 时, position 的 值恰好等于己经读到了多少数据 。
当Buffer 装入数据结束后 ,调用Buffer的flip()方法,该方法将 limit 设置为 position 所在位置,并将 position 设为0,这就使得Buffer的读写指针又移到了开始位置。也就是说,Buffer调用 flip() 方法之后,Buffer为输出数据做好准备 ;
当Buffer 输出数据结束后 ,Buffer调用 clear() 方法,clear() 方法不是清空Buffer的数据,它仅仅将 position 置为0,将limit 置为capacity,这样 为再次向Buffer中装入数据做好准备 。
FileChannel.lockFileChannel.tryLockFileLock.release/close 或 FileChannel.close
需要注意的几点:
在某些系统中,文件加锁仅仅是建议性的,如果一个应用未能得到锁,它仍旧可以向被另一个应用并发锁定的文件执行写操作
在某些系统中,不能在锁定一个文件的 同时将其映射到内存中
文件锁是由整个 Java 虚拟机持有的
在一些系统中,关闭一个通道会释放由 Java 虚拟机持有的底层文件上的所有锁。在同一个锁定文件上应避免使用多个通道
在网络文件系统上锁定文件是高度依赖于系统的,因此应该尽量避免
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 public static void main (String[] args) throws Exception try (FileChannel channel = new FileOutputStream("basic/res/test2.xml" ).getChannel()) {1000 );try (FileChannel channel = FileChannel.open(Path.of("basic/res/test.xml" ))) {try (FileLock lock = channel.tryLock(0 , channel.size(), true )) {
Pattern
Matcher
matches 完成全文匹配find 尝试 查找下一个匹配 ,如果找到了另一个匹配,则返回 truelookingAt
group 分组
replaceAll
编译compile指定模式
CASE_INSENSITIVE 忽略小写,默认情况下,这个标志只考虑 US ASCII 字符UNICODE_CASE ,当与 CASE_INSENSITIVE 组合使用时,用 Unicode 字母的大小写来匹配UNICODE_CHARACTER_CLASSMULTILINEUNIX_LINESDOTALL .符号 匹配所有字符,包括行终止符COMMENTSLITERALCANON_EQ
如果正则表达式包含群组,那么 Matcher 对象可以揭示群组的边界。
startendString group(int groupIndex)groupCount
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 package com.test4;import java.io.*;import java.nio.file.Files;import java.nio.file.Path;import java.nio.file.Paths;import java.util.regex.Matcher;import java.util.regex.Pattern;public class RegexTest private final static Path PATH = Paths.get("basic/res/web.html" );public static void main (String[] args) throws IOException "<img src=\"(.*?)\" alt=\"(.*?)\"" ,"matches: " + matcher.matches());"find: " + matcher.find());while (matcher.find()) {1 ) + "\t" + matcher.group(2 ));
DocumentBuilderFactory.newInstance()DocumentBuilder.newDocumentBuilder()DocumentBuilder.parse()Document.getDocumentElement()NodeListNamedNodeMap
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 package com.test4;import org.w3c.dom.*;import org.xml.sax.SAXException;import javax.xml.parsers.DocumentBuilder;import javax.xml.parsers.DocumentBuilderFactory;import javax.xml.parsers.ParserConfigurationException;import java.io.File;import java.io.IOException;public class Test4 public static void main (String[] args) throws ParserConfigurationException, IOException, SAXException new File("basic/res/test.xml" ));for (int i = 0 ; i < nodeList.getLength(); i++) {if (child instanceof Element element) {": " );if (element.hasAttributes()) {"[" );for (int j = 0 ; j < attrs.getLength(); j++) {": " + attr.getNodeValue());if (j + 1 != attrs.getLength())", " );"]" );else {
<?xml version="1.0" encoding="UTF-8"?> <bookstore > <font > Mono</font > <size > </size > <person name ="mike" age ="23" > <class > 101</class > <phone > 1123912933</phone > </person > </bookstore >
输出
bookstore font: Mono size: 16 person: [age: 23 , name: mike ]
XPath语法: https://www.runoob.com/xpath/xpath-syntax.html
XPathFactory.newInstance()XPath.evaluate()
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 package com.test4;import org.w3c.dom.Node;import org.w3c.dom.NodeList;import org.xml.sax.InputSource;import javax.xml.xpath.XPath;import javax.xml.xpath.XPathConstants;import javax.xml.xpath.XPathExpressionException;import javax.xml.xpath.XPathFactory;import java.io.FileInputStream;import java.io.FileNotFoundException;public class XPathTest public static void main (String[] args) throws FileNotFoundException, XPathExpressionException "//div[@class='content']/div/div/p/a/img/@alt" ,new InputSource(new FileInputStream("basic/res/web2.html" )), XPathConstants.NODESET);for (int i = 0 ; i < nodeList.getLength(); i++) {
在使用 SAX 解析器时,需要一个处理器来为各种解析器事件定义事件动作 。ContentHandler 接口定义了若干个在解析文档时解析器会调用的回调方法 。
startElement 和 endElement 在每当遇到起始或终止标签 时调用characters 在每当遇到字符数据 时调用startDocument 和 endDocument 分别在文档开始和结束 时各调用一次
DefaultHandler 实现了 EntityResolver, DTDHandler, ContentHandler, ErrorHandler 这些接口,这些实现的方法大部分都是不做处理的,因此我们可以自己扩展 DefaultHandler 并重写那些感兴趣的方法。
SAXParserFactory.newInstance()SAXParserFactory.newSAXParser()SAXParser.parse()
startElement 方法有四个参数,如果 命名空间处理特性 已经打开(默认关闭,可以通过 factory.setNamespaceAware(true) 激活),uri和localName提供的就是命名空间和本地(非限定)名
urilocalNameqName 节点标签,比如 img, divattributes 该元素的属性
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 package com.test4;import org.xml.sax.Attributes;import org.xml.sax.SAXException;import org.xml.sax.helpers.DefaultHandler;import javax.xml.parsers.ParserConfigurationException;import javax.xml.parsers.SAXParser;import javax.xml.parsers.SAXParserFactory;import java.io.File;import java.io.IOException;public class SAXTest public static void main (String[] args) throws ParserConfigurationException, SAXException, IOException new File("basic/res/web2.html" ), new DefaultHandler() {@Override public void startElement (String uri, String localName, String qName, Attributes attributes) throws SAXException if (qName.equals("img" ) && attributes != null ) {for (int i = 0 ; i < attributes.getLength(); i++) {"=" + attributes.getValue(i));@Override public void characters (char [] ch, int start, int length) throws SAXException if (!text.isEmpty()) {"Text: " + text);
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 public static void main (String[] args) throws ParserConfigurationException, IOException, TransformerException "info" );"user" );"tony" );"size" , "100" );"LS" , "3.0" );"UTF-8" );"basic/res/out.xml" )));"yes" );"xml" );"UTF-8" );new DOMSource(doc), new StreamResult(Files.newOutputStream(Path.of("basic/res/out.xml" ))));
<?xml version="1.0" encoding="UTF-8" standalone="no"?> <info size ="100" > <user > tony</user > </info >