词法分析
词法分析
词法分析是编译的第一个阶段,词法分析器 首先读取源程序,将他们组成 词素,并生成输出一个 词法单元序列。
每一个词法单元对应一个词素,同时词法分析器还和 符号表 进行交互,当词法分析器发现一个 标识符 的词素时,将其加入到符号表中。
词法分析器除了在编译阶段读取源程序之外,还会过滤一些词素之外的不必要的信息(空白字符、注释),而且也会将错误信息 和源程序的位置关联起来。
词法单元、模式、词素
- 词法单元:形如 之类的,即由一个词法单元名字(抽象符号)和可选的属性值组成。
- 模式:字符序列,也就是用于匹配词素的字符串
- 词素:基本字符序列
一个标识符的属性值是一个指向符号表中该标识符对应的条目的指针。
缓冲区对/双缓冲区
每个缓冲区的容量是N个字符,通常 N 是一个磁盘块的大小。我们可以用系统读取命令一次将 个字符读入到缓冲区中,而不是每次都读取一个字符,这样效率太低了。
程序为输入维护了两个指针:
- lexemeBegin 指针:该指针指向当前词素的开始处。当前我们正在确定这个词的结尾
- forward 指针:他一直向前扫描,直到发现某个模式被匹配为止。
一旦确定了下一个词素,forward 指针将指向该词素结尾的字符。
哨兵标记
如果我们扩展每个缓冲区,使他们在末尾包含一个 哨兵(sentinel) 字符 ,我们就可以把对缓冲区末端的测试和对当前字符的测试合二为一。这个哨兵字符必须是一个不会在源程序中出现的字符,一个自然的选择就是 eof
带有哨兵标记的forward指针移动算法
1 | |
串和语言
字母表(alphabet)是一个 有限 的符号集合。比如集合 是一个二进制字母表。
某一个字母表上的一个串(string)是该字母表中符号的一个 有穷序列 。
串 的长度记作 表示 中符号出现的次数。空串 是一个长度为0的串。
串的各部分术语
- 串的 前缀prefix 是指从 的尾部删除0个或多个符号后得到的串
- 串的 后缀suffix 是指从 的开始处删除0个或多个符号后得到的串。
- 串的 子串substring 是指从 中删除某个前缀和某个后缀之后得到的串。
- 串的 真前缀、真后缀、真子串 分别是指 的既不等于 ,也不等于 本身的前缀、后缀和子串。
- 串的 子序列subsequence 是从 中删除0个或多个符号后得到的串,这些被删除的符号可能不相邻。
如果 和 是串,则将它们 连接 为 。类似可得到了 看作 的 个连接。
语言上的运算
一个语言 的 kleene 闭包(closeure) (也就是 自身连接n次 ) ,记作 ,即:将 连接 0次或多次 后得到的串集,注意 被定义为 ,并且 被归纳地定义为 。 的 正闭包 不包含
| 运算 | 定义和表示 |
|---|---|
| 和 的并 | $L\cup M={s |
| 和 的连接 | $LM={st |
| 的 Kleene闭包 | |
| 的正闭包 |
正则表达式
归纳基础
- $\epsilon $ 是一个正则表达式, ,该语言只包含空串
- 如果 是字母表 上的一个符号,那么 是一个正则表达式,并且
归纳步骤
由小的正则表达式构造较大的正则表达式需要4个步骤
- 是一个正则表达式,表示语言
- 是一个正则表达式,表示
- 是一个正则表达式,表示
- 是一个正则表达式,表示 ,加括号
去掉括号的约定:
- 一元运算符 具有最高的优先级,并且是左结合的。
- 连接 具有次高的优先级,也是左结合的。
- 的优先级最低,也是左结合的。
比如将 改写为
正规式性质:
R|S=S|R
R(S|T)=(R|S)|T
R(ST)=(RS)T
R(S|T)=RS|RT
(R|S)T=RT|ST
eR=Re=R
规定 ,,则称 R* 是 R的闭包(零次或多次)。此外 R+ =RR*,也就是 R的正则闭包(R和R* 连接:一次或多次,也就是消掉的 )。
正规式是一个正则表达式,而正规集是用字母表中的字母描述这个正则表达式的 所有串集合
例子:令 ,设 是 上的正规式,求正规集。
// 连接
正则表达式的扩展
- 一个或多个实例 , 表示
- 零个或多个实例 , 等价于 ,换句话说就是
- 字符类,一个正则表达式 可以缩写为 。当 形成一个逻辑上的序列时,比如大些字母小写字母或数位时,可以将其表示为 [ 。
例1:将 C语言中的 标识符 对应的正则定义为表示出来
例2:表示无符号数的正则定义
保留字的识别
- 初始化时就将各个保留字填入字符表中,符号表中的某个字段会指明这些串并不是普通的标识符,并指出他们所代表的词法单元。
- 为每个关键字建立一个单独的状态转换图。
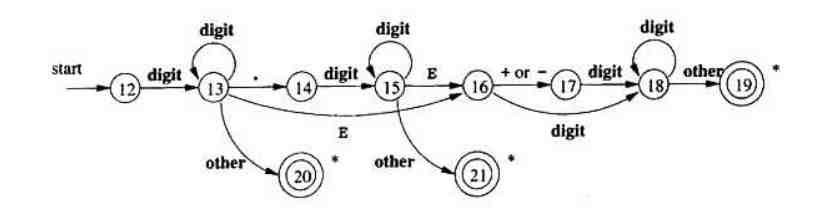
例子:一个关于数字的状态转换图如下
这个状态转换图首先从start开始,即当前的状态为12,当读取到一个数字时,其将会跳转到状态13,相注意,如果此时仍然是数字,那么还会继续处在13处,也就是说直到读取到的不是 数位、小数点、E时才会结束,对于 3.1415 小数,它首先读取出3,然后再在 . 的驱动下跳转到 状态14,之后继续读取。
有穷自动机
有穷自动机分为两类:
- 不确定的有穷自动机(Nondeterministic Finite Automate,NFA)对其边上的标号没有任何限制。一个符号标记离开同一个状态的多条边 ,空串 $\epsilon $ 也可以作为标号
- 确定的有穷自动机(Deterministic Finite Automate,DFA)对于每一个状态及其自动机输入的符号有且只有一条离开以该符号为标号的边
有穷自动机可以定义 空语言
NFA
组成部分:
- 一个有穷的状态集合
- 一个输入集合 (输入字母表,且假设 $\epsilon $ 不在 中)
- 一个转换函数 ,他为每个状态和 中的每个符号都给出了一个相应的 后继状态 的集合。
- 中的一个状态 被指定为一个 开始状态/初始状态。
- 中的一个子集 被指定为 接受状态/终止状态的集合。

同一个符号可以标记从一个状态出发到达多个目标状态的多条边。
一条边的标号不仅可以是输入字母表 中的字符,也可以是 (正常来看似乎毫无意义,但是对于NFA就不一样了)。
例子:,其中 形成一个闭包,因此在状态转换图中应该是 从状态0在 或 的驱动下可以转到当前自身状态0(多次连接)。
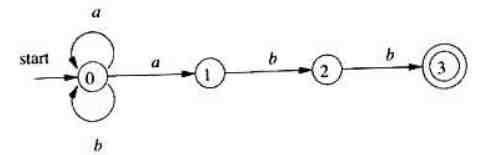
转换表
可以将NFA转换为一张 转换表,表中各行对应状态、各列对应输入符号和 $\epsilon $,上面的状态转换图对应的转换表如下:
比如状态 0 ,在字符a的驱动下可以到达的状态集合为 、在字符 b的驱动下可以达到的状态集合为
| 状态 | a | b | c |
|---|---|---|---|
| 0 | {0,1} | {0} | |
| 1 | {2} | ||
| 2 | {3} | ||
| 3 |
从正则表达式构造NFA
将正则表达式转换为一个NFA的为 McMaughton-Yamada-Thompson算法
汤普森构造法是C语言&Unix之父之一的肯·汤普森(Ken Thompson)提出的构造识别正则表达式ε-NFA的方法,其原理非常简单,先构造识别子表达式的 ,再通过几个简单的规则将ε-NFA合并,最终得到识别完整正则表达式的ε-NFA。汤普森构造法的优点是构造速度快,且构造的ε-NFA状态数较少。
输入:字母表 上的一个正则表达式
输出:一个接受 的NFA
基本规则:对于正则表达式 ,构造如下NFA
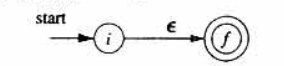
对于字母表 中的子表达式 ,构造如下NFA
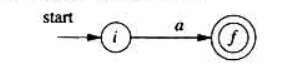
归纳规则:假设正则表达式 和 的NFA分别为 和
-
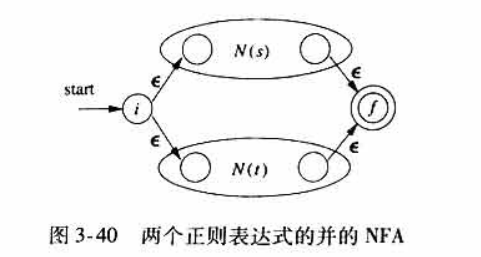
从上面这幅图可以看到,NFA的 的一个明显作用是对于 选择 来说划分了不同的分支 而不会影响原有的语义表示
-
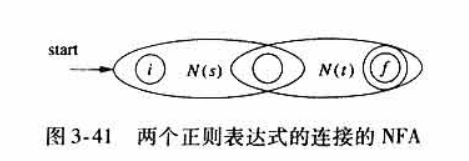
-
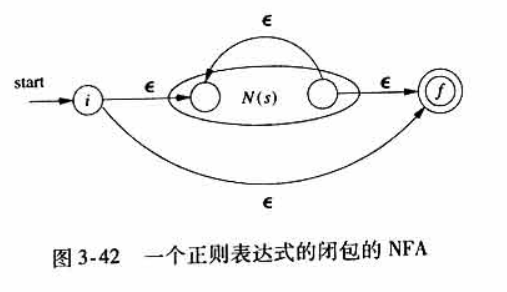
由于 闭包 表达的意思是:匹配前面的子表达式零次或多次。,因此这里也需要 来跳过当前不需要匹配的子表达式。这里也体现出 的选择作用(展开分支)。
对比 并 和 闭包 发现,两者有明显的相同点,即将 中 替换为 ,同时在从 的出状态向入状态添加一个 形成循环就可以得到一个闭包的状态转换图。
-
,那么
- 的状态最多为 中出现的运算符和运算分量的总数的2倍,因为算法的每一步构造步骤最多只引入两个状态。
- 有且只有一个开始状态和一个接受状态,开始状态没有入边、接受状态没有出边。
- 中除了接受状态之外的每个状态要么有一条其标号为 中符号的出边,要么有两条标号为 的出边(注意这里最多两条 出边!)。
NFA合并
合并的方法是引入一个新的开始状态,从这个新开始状态到各个对应于模式 的NFA 的开始状态各自有一个 转换。
个人理解: 的作用就表示该处不需要字符驱动就能 移动到下一个状态,换句话说就是 起到了 选择| 跳转的作用,当然在合并多个子NFA时也是选择作用。
由NFA构造DFA的子集构造算法
输入:一个NFA
输出:一个接受同样语言的DFA
方法:算法为D构造一个转换表。,D的每一个状态是一个NFA状态集合注意, 表示 的单个状态,而 代表 的一个状态集。
| 操作 | 描述 |
|---|---|
| 能够从 NFA的状态 开始只通过 转换到达的 NFA状态集合 | |
| 能够从 中某个 NFA的状态 开始只通过 转换到达的 NFA状态集合。即 | |
| 能够从 中某个状态 出发通过标号为 的转换到达的NFA状态的集合,一旦达到便停止。 | |
| 能够从 中某个状态 出发通过标号为 的转换,然后再经过 几个 $\epsilon $转换到达的 NFA状态集合。即 。总之意思就是T中的状态s先经过 一次a后再经过多个 标号可以到达(凡是经过的状态也算在内)的所有状态集合。 |
子集构造法伪代码如下
1 | |
以下面这个NFA为例子
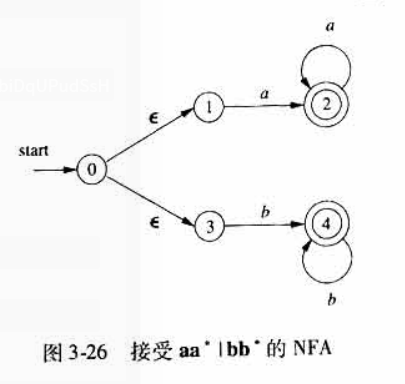
我们从 状态开始分析,从0开始经过 转换可以达到的状态集合有多个, NFA的初始状态为 。注意这里包含了0本身,因为路径可以不包含边,所以状态0也可以从他自身出发经过标号为 的路径达到的状态。此时 只有唯一的 状态集合 。
-
将 加上标记,对于每一个输入符号 :
- 。PS:这里设置了一个新的记号
由于和 都不在 中,因此将加入到得 ,同时也加入到转换表 ,
-
将 加上标记,对于每一个输入符号 :
- 。注意这里的 已经存在于 ,因此不需要再次添加进去,但是还是需要将其加入到 转换表中 。
- ,空集也是一样的。
-
将 加上标记,对于每一个输入符号 :
- ,加入到 转换表
- ,加入到 转换表
最终得到转换表
| NFA State | DFA State | a | b |
|---|---|---|---|
| {0,1,3} | A | B | C |
| {2} | B | B | ∅ |
| {4} | C | ∅ | C |
其DFA状态转换图(其中的 空集/死状态 不需要标出来):
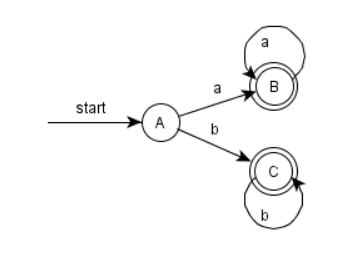
注意,原来的NFA的终态为 2 ,4,而转化后的DFA中的状态 B和C 分别含有原来的终态 2,4 而成为DFA的终态。
DFA的化简
对NFA确定后的DFA可能有多余的状态,因此需要对其进行化简,即化简后的DFA满足
- 没有多余状态
- 在其集中,没有两个相互等价的状态存在,所谓等价指的是从 s1或s2在串s的驱动下都能够到达终态。
方法:
- 首先将 DFA M的状态集 S 中的 终态 和 非终态 划分开,形成两个子集,作为基本划分。
- 对当前 已经划分出的 子集,看每一个 是否能够进一步划分:即对某一个 ,若存在一个输入字符 () ,使得 不全包含在当前划分的某一个子集 中(也就是跨越两个子集,不属于同一个子集。换句话说就是如果属于同一个子集,说明这两个终态集是 重复 的,为了我们的目的是化简DFA,因此对于那些重复的终态集不需要划分开来),就将 一分为二。
- 重复步骤2,直到子集个数不再增加为止(每一个子集不可再分)。
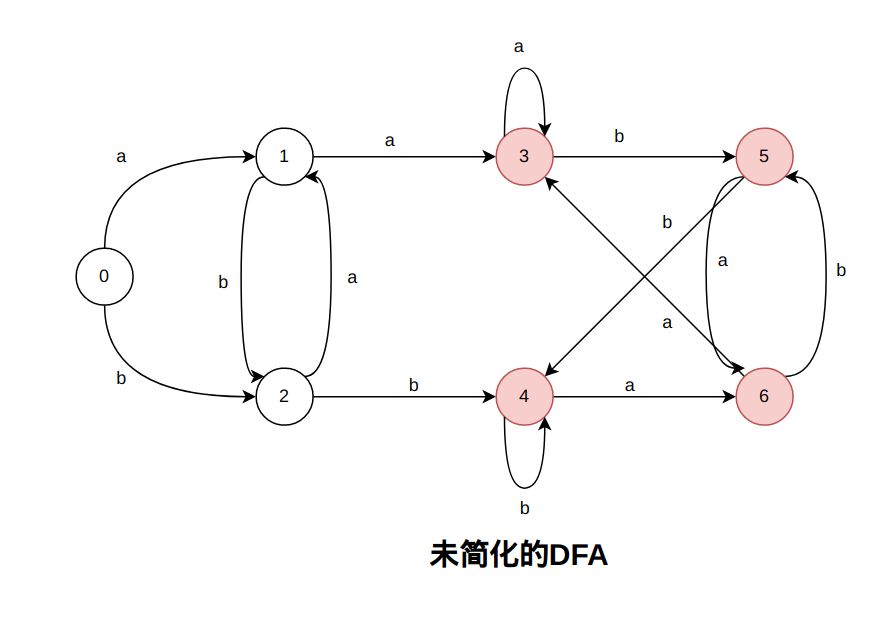
例子
-
首先将状态集合 划分为 终态集 {3,4,5,6} 和 非终态集 {0,1,2}
-
对于 {0,1,2} 在 字符 a驱动下,,而 ,分别属于非终态集和终态集,因此将 {0,1,2} 划分为 {0,2} 和 {1}。此时的划分集合为 {1} 、{0,2}、{3,4,5,6}
-
对于 {0, 2} ,在 字符 b驱动下,,,属于不同的终态集合,因此划分 {0,2} 为{0} 和 {2}
-
对于 {3,4,5,6} ,在 字符 a驱动下,,都属于终态集,因此不需要划分。
-
对于 {3,4,5,6} ,在 字符 b驱动下,,都属于终态集,因此不需要划分。
-
最后按照顺序重新命名终态子集 {0}, {1}, {2}, {3,4,5,6} 为 0,1,2,3,得到新的终态转换矩阵DFA M’(注意,终态为3)
| S | a | b |
|---|---|---|
| 0 | 1 | 2 |
| 1 | 3 | 2 |
| 2 | 1 | 3 |
| 3 | 3 | 3 |
对应的转换图为 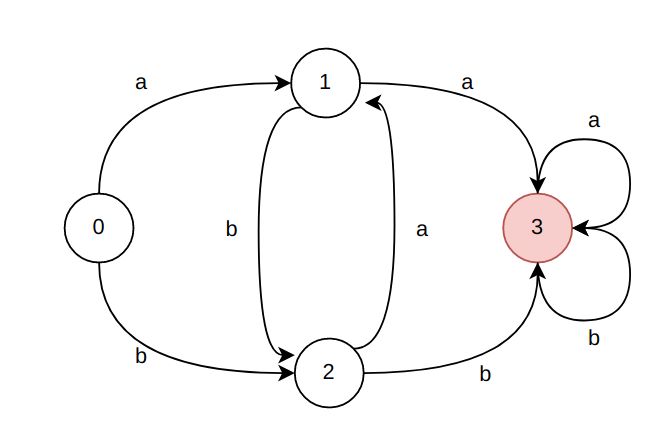
例子2
构造一个DFA,他接受 上所有 满足 字符串中每个a都有至少一个b直接跟在右边 的字符串。
根据题意,得到正则表达式为
NFA构造如下
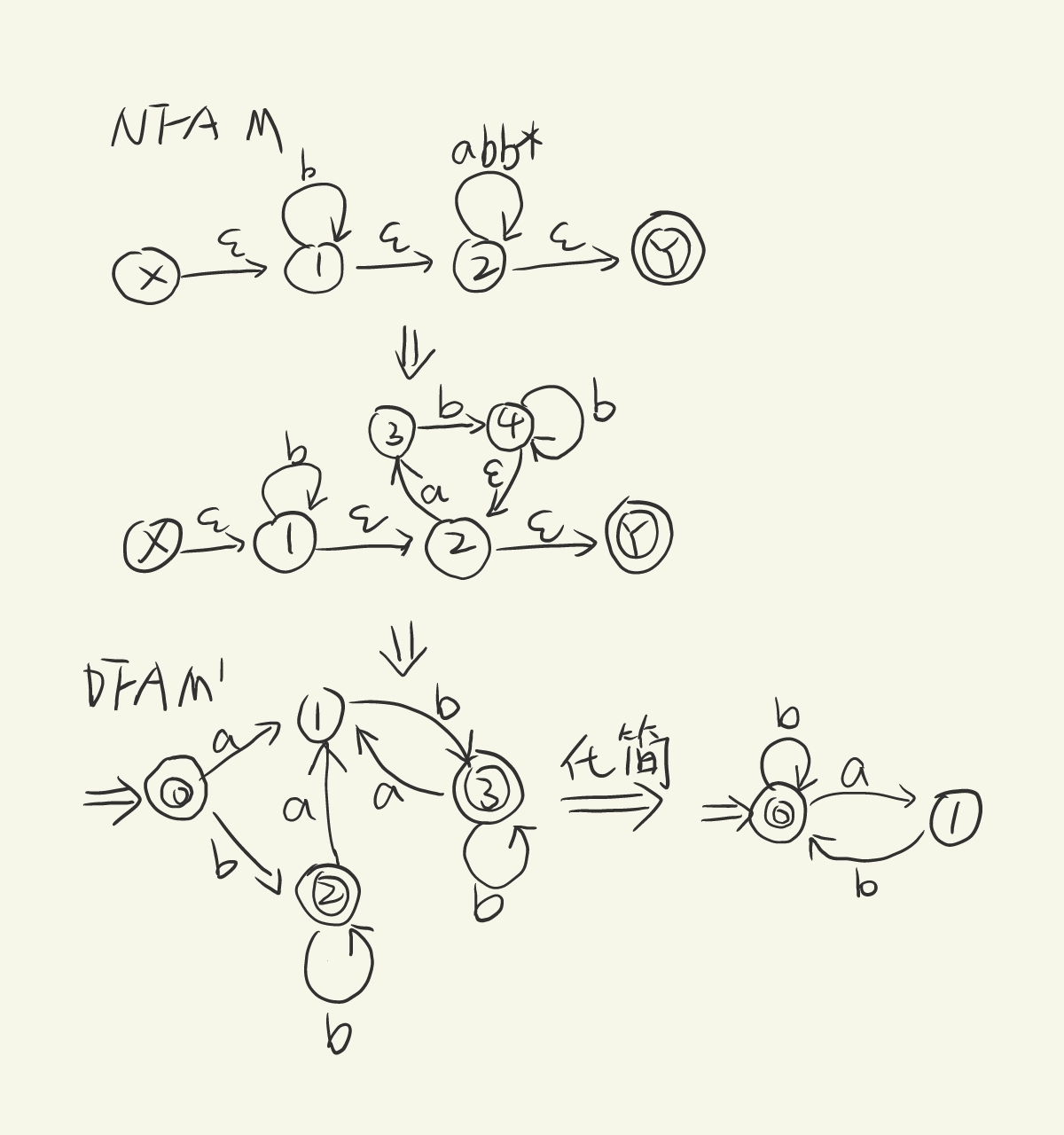
转换表:
| S | a | b |
|---|---|---|
| {X,1,2,Y} | {3} | {1,2,Y} |
| {3} | - | {4,2,Y} |
| {1,2,Y} | {3} | {1,2,Y} |
| {4,2,Y} | {3} | {4,2,Y} |
终态转换矩阵
| S | a | b |
|---|---|---|
| 0 | 1 | 2 |
| 1 | - | 3 |
| 2 | 1 | 2 |
| 3 | 1 | 3 |
因此得到确定的DFA M如上图。化简得到的转换表:
| S | a | b |
|---|---|---|
| {X,Y} | {1} | {X,Y} |
| {1} | - | {Y} |
| {Y} | {1} | {Y} |
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!