跳跃表/跳表(SkipList)O ( log n ) O(\log n) O ( log n ) O ( log n ) O(\log n) O ( log n ) n n n
由于本人知识有限,对于跳跃表的认识可能不够深入,不过还是想把自己的看法写下来…初学跳跃表时也许无法理解,不过当深入理解了跳跃表的原理时,一切都变得easy。比起手写一个红黑树代码跳跃表要简单得多,而且跳跃表也有很多实现例子的,如 Qt中的 QMap ,MemSQL ,Redis… 虽然我都没有接触过…
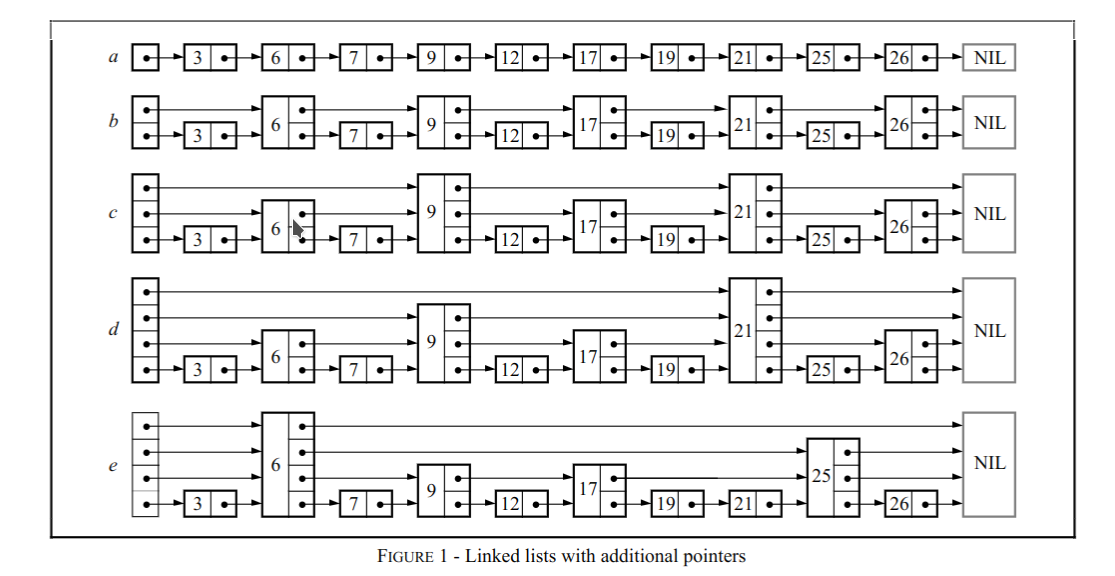
一个简单的跳跃表结构
我们都知道,对一个 有序链表 执行查找的复杂度为 O ( n ) O(n) O ( n ) 二分查找 的复杂度则是 O ( log n ) O(\log n) O ( log n ) 有序链表的查找问题(当然还要其他更重要的作用),使其复杂度将为 O ( log n ) O(\log n) O ( log n ) O ( n ) O(n) O ( n )
利用跳跃表之后的查找、插入、删除复杂度如下
方法
查找
插入
删除
平均情况
O ( log n ) O(\log n) O ( log n ) O ( log n ) O(\log n) O ( log n ) O ( log n ) O(\log n) O ( log n )
最坏情况
O ( n ) O(n) O ( n ) O ( n ) O(n) O ( n ) O ( n ) O(n) O ( n )
跳跃表是一个空间换时间的数据结构。
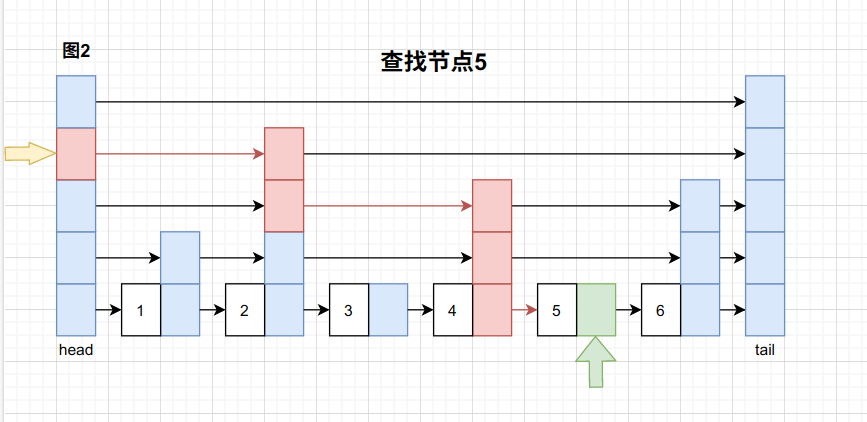
那么跳跃表是如何实现快速查找的呢?跳跃表通过建立 索引节点 ,每次查找时,先通过最顶层索引节点一层层的向下寻找满足条件的节点,每次查找都有可能跨越到其他不相邻的节点,直到抵达最底层也就是原始层链表某处节点位置。
这里的 索引节点 其实就是一组节点地址,在new一个新节点时就分配好,然后在对每一层索引节点进行重组,使其前后串联起来,这样就形成了一个 i i i i ∈ ( 0 , M − 1 ) i\in(0,M-1) i ∈ ( 0 , M − 1 )
要查找key为5的节点,那么从head开始一层层的查找,此次过程跳过了节点1和节点3,最后找到了节点5。
这里我们设置一个有序链表为带有head和tail节点,其中head节点的next指针就是有序链表的起始,而tail节点一般为nullptr,不过这里我们将tail作为哨兵节点,这样就无需处理nullptr问题了。
在一个规则跳表结构中,i i i n 2 i \frac{n}{2^i} 2 i n n n n 0 → i 0 \rightarrow i 0 → i n , n 2 , n 4 , ⋯ , n 2 i n,\frac{n}{2},\frac{n}{4},\cdots,\frac{n}{2^{i}} n , 2 n , 4 n , ⋯ , 2 i n
也就是说,我们希望在插入时符合这种结构,而插入的节点属于i i i 1 2 i \frac{1}{2^i} 2 i 1 1 2 \frac{1}{2} 2 1 ⋯ \cdots ⋯ i i i 1 2 i \frac{1}{2^i} 2 i 1
这时来看看这段话,摘自William Pugh(就是他搞出了跳表)写的论文里的一段话。
原文跳跃表使用概率平衡而不是严格执行的平衡 。因此,在跳跃表中插入和删除的算法是要比等效算法简单得多,也快得多平衡树。
注意 跳跃表使用概率平衡而不是严格执行的平衡 这告诉我们,插入操作是动态的插入到不同层级的位置。因此,把一个新节点插入到i i i p i p^i p i p = 0.5 p=0.5 p = 0 . 5
而这个动态插入法就利用到 随机数生成函数 来完成,一个好的随机数生成函数,能够使跳表结构达到最优的效果使其复杂度不会太高。
除此之外每一次插入/删除操作,都必须要维护跳表结构,也就是处理好链表节点的指向关系,避免混乱。
不说那么多,级的分配可以利用一个随机数生成函数来完成。
randomLevel ()1 random () that returns a random value in [0. ..1 )while random () < p and lvl < MaxLevel do 1 return lvl
转化成C++代码
int random_level () int level= 1 ;while (((double )(rand ()%101 )/101 ) < (m_prob) return level;
这里还要一个糟糕的随机数生成函数仅供参考
int random_level () int level = rand () % m_maxLevel + 1 ;return level;
OK,现在开始用C++实现跳跃表
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 template <class KeyType ,class ValueType >struct Element {Element (){}Element (KeyType key,const ValueType& value){this ->key=key;this ->value=value;template <class KeyType ,class ValueType >struct skipNode {skipNode (const Element<KeyType,ValueType>&theElement,int size){this ->element=theElement;this ->next=new skipNode<KeyType,ValueType>*[size];
MaxLevel太大,造成空间的浪费,太小又会导致退化成一个冗杂的 ‘单链表’ 结构,两者均会影响跳跃表的性能。因此合适的MaxLevel十分重要。
从《Skip Lists: A Probabilistic Alternative toL ( n ) = ⌈ l o g 1 p n ⌉ L(n)=\lceil log_\frac{1}{p}n \rceil L ( n ) = ⌈ l o g p 1 n ⌉ M a x L e v e l = L ( N ) , N MaxLevel=L(N),N M a x L e v e l = L ( N ) , N
利用换底公式 log a b = log c b log c a \log_ab=\frac{\log_cb}{\log_ca} log a b = log c a log c b
int MaxLevel (int numberOfnode,float prob) return (int )(ceil (logf ((float )numberOfnode)/logf ((float )1 /prob)));
我们只需在构造函数进行初始化即可。MaxLevel,也可以通过numberOfnode来计算一个MaxLevel
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 template <class KeyType ,class ValueType >skiplist (float prob,KeyType tailLargeKey,int max_level,int numberOfnode) {srand (time (nullptr ));0 ;if (numberOfnode!=-1 )MaxLevel (numberOfnode,prob);else 0 ;0 };new skipNode<KeyType,ValueType>(tailPair,0 );new skipNode<KeyType,ValueType>(tailPair,m_maxLevel);for (int i = 0 ; i < m_maxLevel; i++){new skipNode<KeyType,ValueType>*[m_maxLevel];
尾节点内存分配类似malloc(0)形式
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 template <class KeyType ,class ValueType >search (const KeyType&key){for (int i = m_curMaxLevel-1 ; i >= 0 ; --i){while (forwardNode->next[i]!=m_tailNode&&forwardNode->next[i]->element.key<key){this ->m_forwardNodes[i]=forwardNode;return forwardNode->next[0 ];template <class KeyType ,class ValueType >find (const KeyType&key){if (key > this ->m_tailKey)return nullptr ;for (int i = m_curMaxLevel-1 ; i >=0 ; --i){while (forwardNode->next[i]!=m_tailNode && forwardNode->next[i]->element.key < key){if (forwardNode->next[0 ]->element.key==key){return &forwardNode->next[0 ]->element;else {return nullptr ;
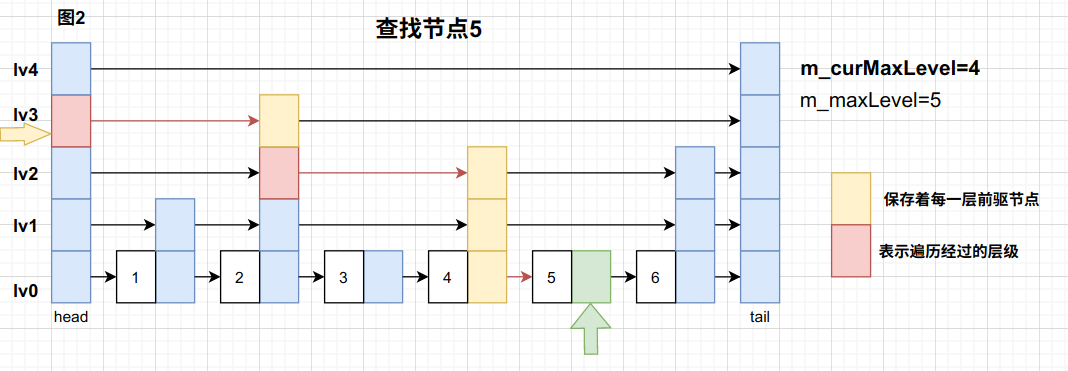
其中find和search都是从当前最大层级依次向下遍历,不同的是,search在遍历的同时将每次遍历到每一层的前驱节点保存在m_forwardNodes中,目的是为了衔接后面的插入/删除节点
其中的 forwardNode->next[0] 就是下一个要查找的节点(如果存在的话)
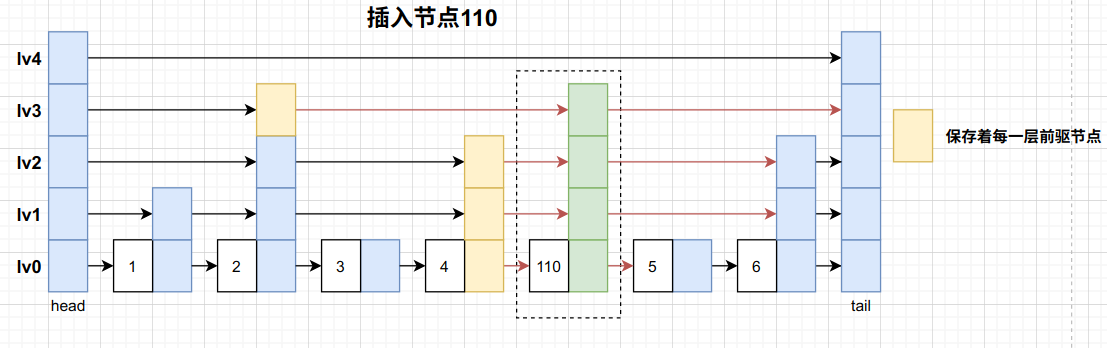
每一次插入,需要通过search保存 前驱节点m_forwardNodes 从而将待插入节点连接起来。如下图红色箭头表示前后需要链接的节点。有序链表,下图只是为了解释而已 (其实是当时不小心画错了… 😦)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 template <class KeyType ,class ValueType >void skiplist<KeyType,ValueType>::insert (const Element<KeyType,ValueType>&element){int level=random_level ();if (level > this ->m_curMaxLevel){this ->m_curMaxLevel=level;search (element.key);if (pNode->element.key==element.key){return ;new skipNode<KeyType,ValueType>(element,level);for (int i = level-1 ; i >=0 ; --i){
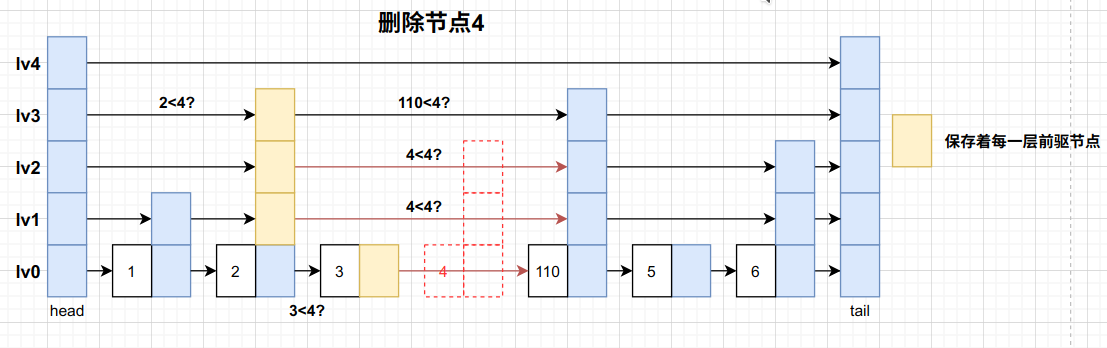
删除操作类似插入操作,也需要通过search保存 前驱节点m_forwardNodes
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 template <class KeyType ,class ValueType >bool skiplist<KeyType,ValueType>::erase (const KeyType&key){if (key>m_tailKey)return false ;search (key);if (pNode->element.key!=key)return false ;for (int i = m_curMaxLevel-1 ; i >= 0 ; --i){if (m_forwardNodes[i]->next[i]==pNode)while (m_curMaxLevel-1 > 0 &&m_headNode->next[m_curMaxLevel-1 ]==m_tailNode){delete pNode; return true ;
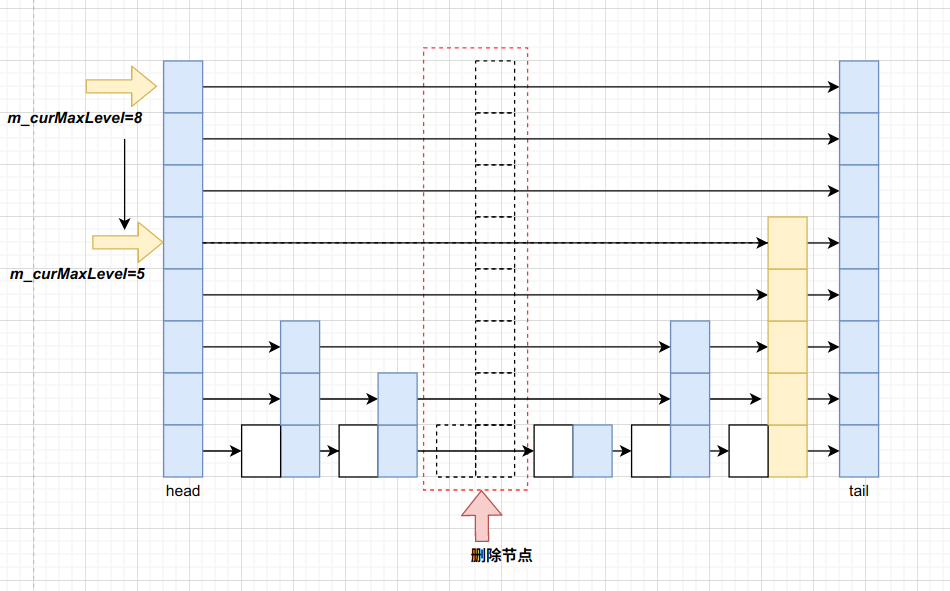
需要注意的是,删除节点后还要维护m_curMaxLevel使其不能太高,这样的话可以减少遍历次数。
在析构函数中释放所有内存
template <class KeyType ,class ValueType >skiplist (){while (m_headNode!=m_tailNode){auto x=m_headNode->next[0 ];delete m_headNode;delete m_tailNode;delete []m_forwardNodes;
用skiplist和STL map测试插入操作,仅供参考
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 #include <map> #include <iostream> #include "skiplist.h" #include "ClockTest.h" using namespace std;#define TAIL_INFINITY_KEY 0xffffff int main (int argc, char const *argv[]) int n=1000000 ;srand (time (nullptr ));start_timeclock ();skiplist<int ,int > sk (0.5 ,TAIL_INFINITY_KEY,0 ,n) ;for (int i = n; i >= 0 ; --i){insert (Element<int ,int >{rand ()%n,i});stop_timeclock ();auto skiplist_insert_time=CClock::time_duration ();start_timeclock ();int ,int > mp;for (int i = n; i >=0 ; --i){insert (pair<int ,int >(rand ()%n,i));stop_timeclock ();auto map_insert_time=CClock::time_duration ();start_timeclock ();for (int i = n; i >=0 ; --i){find (rand ()%n);stop_timeclock ();auto skip_find_time=CClock::time_duration ();start_timeclock ();for (int i = n; i >=0 ; --i){find (rand ()%n);stop_timeclock ();auto map_find_time=CClock::time_duration ();start_timeclock ();for (int i = n; i >=0 ; --i){erase (rand ()%n);stop_timeclock ();auto skip_erase_time=CClock::time_duration ();start_timeclock ();for (int i = n; i >=0 ; --i){erase (rand ()%n);stop_timeclock ();auto map_erase_time=CClock::time_duration ();"SkipList insert time: " <<skiplist_insert_time<<endl;"SkipList find time: " <<skip_find_time<<endl;"SkipList erase time: " <<skip_erase_time<<endl;"Map insert time: " <<map_insert_time<<endl;"Map find time: " <<map_find_time<<endl;"Map erase time: " <<map_erase_time<<endl;"SkipList size: " <<sk.size ()<<endl;"Map size: " <<mp.size ()<<endl;return 0 ;
我机器上测试 随机插入/查找/删除,结果仅供参考。单位秒
insert
find
erase
skiplist1
1.44737
2.03802
2.158
skiplist2
1.34377
1.61364
1.52145
skiplist3
1.35671
2.31105
1.57659
map1
1.48519
1.28156
1.93228
map2
1.00754
1.099
1.29245
map3
1.23837
1.28021
1.35214
由此可见,跳跃表也是很高效的一种数据结构
skiplist源码地址: https://github.com/josexy/skiplist_c
维基百科-skiplist Skip Lists: A Probabilistic Alternative toBalanced Trees 浅析SkipList跳跃表原理及代码实现