LZW文本压缩
最近翻看《数据结构、算法与应用》里面关于哈希表章节时看到一个LZW文本压缩算法的实例,啃了很久才基本了解LZW算法,于是赶紧把它记录下来方便日后翻看。
LZW
Lempel-Ziv-Welch(LZW)是由Abraham Lempel,Jacob Ziv和Terry Welch创建的无损数据压缩算法。
为了减少一个文本文件占用的磁盘空间,通常需要将文本文件压缩编码后存储,这个过程需要对文件编码的压缩器compressor,以及解码的解压器decompressor。
压缩compress
LZW压缩方法是将文本字符串Text映射为数字编码Code(比如ASCII 0-255),而将文本字符串Text和数字编码Code这一对映射关系存储在字典/哈希表中。
首先我们规定:p表示存在于字典中最长的字符串,称为前缀字符串;c表示在待编码字符串S中匹配到的p前缀字符串的下一个字符,称为后缀字符;p在字典表table中的代码为table[p]。
为了简化事例,假设一串文本S=aaabbbbbbaabaaba只由a、b组成,初始情况下字典中只有a和b这两个字符,且存储在字典table中,已压缩串为空。
这张图参考了书上的例子,加上自己修改觉得挺不错的。图中表格阴影部分表示输出的压缩串代码在字典中的位置。
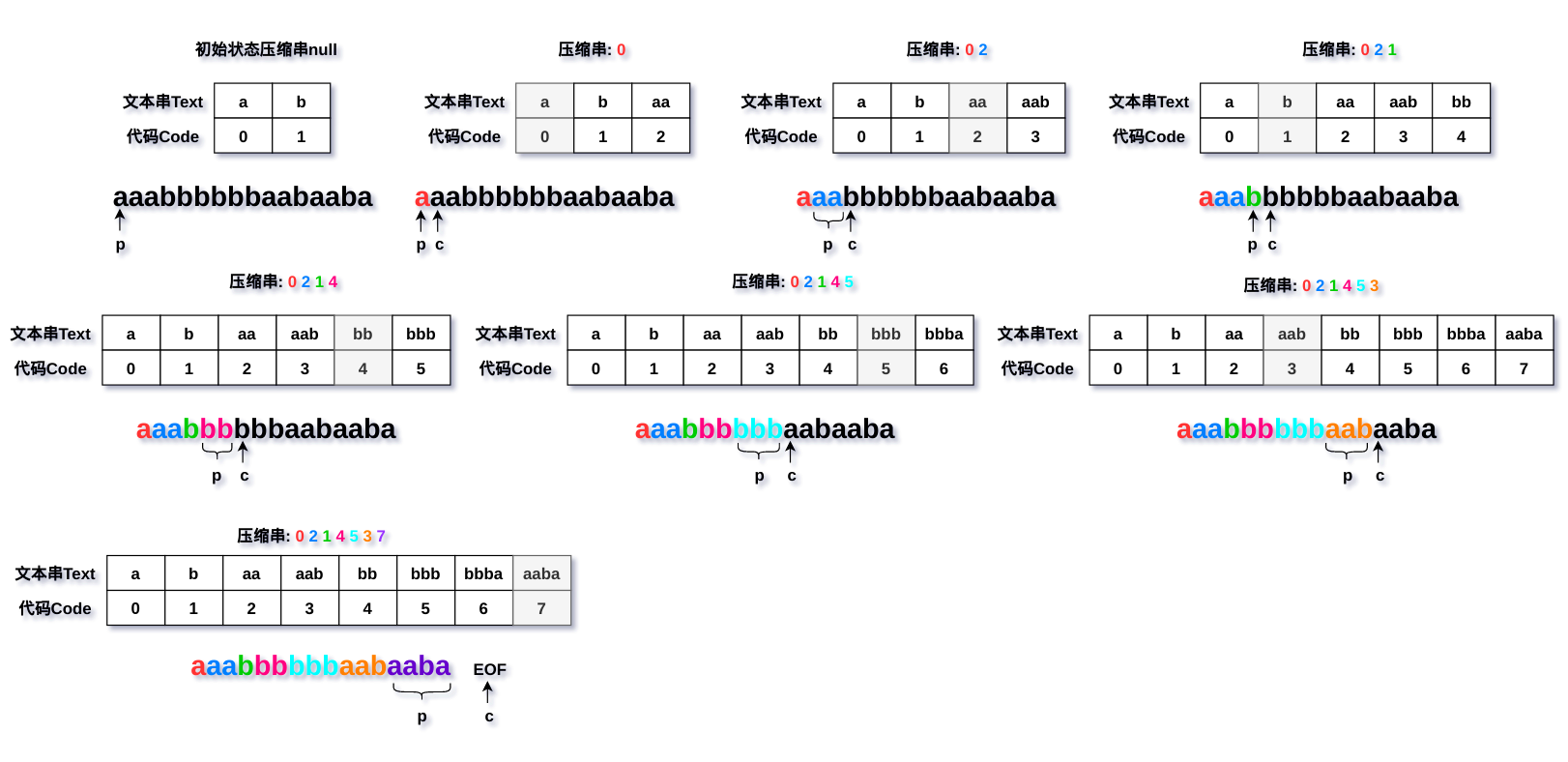
用LZW压缩算法来模拟上图的过程:
1.首先初始化字典table<String,Integer>;
2.然后找到待编码字符串S的第一个字符作为前缀字符串p,且这个字符一定能在字典中找到对应代码table[p];
3.接着读取S的下一个字符作为后缀字符c=a;
4.如果p+c在字典中,则p指向下一个字符串:p=p+c;
5.如果p+c不在字典中,那么输出p在字典中的代码table[p],同时为p+c在字典中分配一个新的代码table[p+c],p指向下一个字符:p=c;
6.重复步骤3、4、5直到EOF;
7.最后输出代码table[p];
8.结束。
伪代码如下
1 | |
初始字典仅仅包含一些基本字符串和代码,但是随着编码的进行,字典不断扩增,如果遇到一个新的字符串p+c不在字典中,那么就将其添加到字典,以便下一次编码时p+c能够从字典中找到;如果能够在字典中找到p+c,意味着需要一个更长的字符串p来映射一些新的代码以达到文本压缩目的。就像上图例2,3,此时p=a,c=a,<aa,2>已经存在字典,下一次判断p+c=aa就能够在字典中找到aa,于是p=p+c=aa,尽可能选择一个最长的前缀字符串,接着下一次判断时aa+b=aab在字典中找不到,于是将<aab,3>插入到字典中。
还有当读取文件尾/字符串到达结尾时,此时p还保留之前的字符串p=c或p=p+c,而且一定能在字典中找到。这是因为单个字符p=c在初始字典table时就已经有对应的代码了,而p=p+c要成立,那么它必须是插入p+c之后才能得到,也就是说,“输出”慢于“插入”。于是编码结束时,还要将对table[p]处理(输出)才算是完整的LZW编码。
于是,压缩文本中并没有包含在编码过程中的生成的字典,而是通过编码的进行不断生成新的<新字符串前缀,新的代码>,而且注意到,将文本编码后的代码输出也只是前缀字符串p。
解压缩decompress
与压缩对应的便是解压缩,其实lzw解压缩与lzw压缩是互逆的,但要理解它是怎么处理的需要些功夫。
在前面的压缩compress时,定义一个初始字典,且映射关系为<文本串,代码> => table<String,Integer>。同样,解压缩也需要一个字典:table<Integer,String>。
由于解码的过程中,解码器得到的是一个代码数字int,那得考虑代码在不在字典内,以及对应的解码文本是什么。
首先需要规定:p表示当前读取到的待解码串S中某一个代码,其对应的文本为text(p)(或者table[p]如果存在的话);q表示出现于p之前的代码,可称为前缀代码,而且该代码q一定存在字典里,其对应的文本为text(q);fc(p)表示text(p)的第一个字符(first character),可称为后缀字符。
还是以上面的例子来说明,存在已经编码的代码串0214537。图中表格阴影部分表示将新的<代码,文本>添加到字典中。
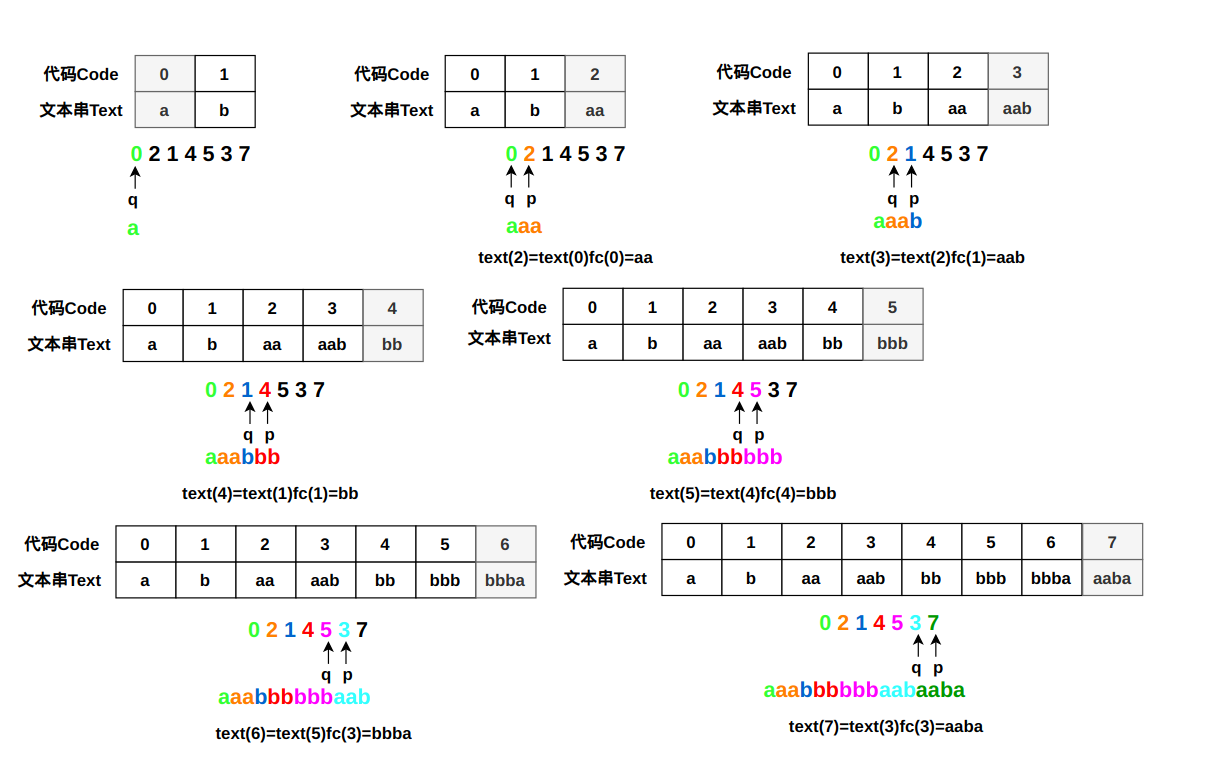
LZW解码过程如下:
1.首先初始化字典;
2.然后找到S的第一个代码q,而且该代码一定存在字典内(这是由编码时决定的),输出文本text(q);
3.接着读取S的下一个代码p;
4.如果p在字典里,则输出对应的文本text(p),同时向字典添加新的代码text(q)fc(p);
5.如果p不在字典里,则向字典添加新的代码text(p)=text(q)fc(q),输出对应的文本text(p);
6.重复步骤3、4、5,直到EOF;
7.结束。
伪代码如下:
1 | |
1.p在字典里
以代码p=1和代码q=2为例。
现在根据解压缩的情况来分析:已知代码p在字典里,说明在编码过程(此时p表示代码对应的文本)中输出代码table[p]=1之前的某一步骤输出了代码table[q]=2,同时添加新的文本q+c=aa+b=aab到字典里且table[q+c]=3(这也就是解码时的text(q)+fc§,c=fc§),然后q=c=b;之后继续判断q+c=b+b=bb不在字典内,则输出table[q=b]=1。于是就形成了代码2 1的情况。
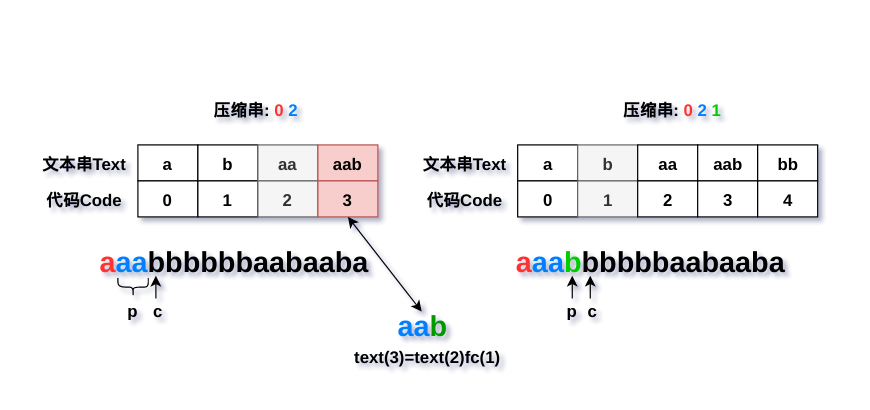
还有5 3这种情况
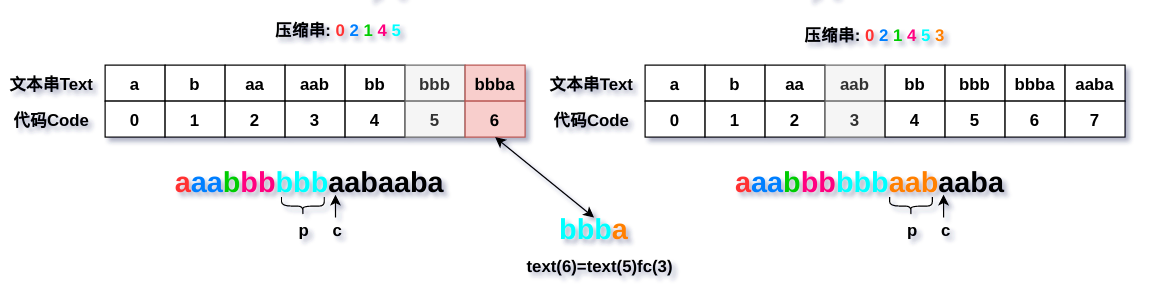
2.p不在字典里
这种情况只有在文本段中形式为text(q)text(q)fc(q)和text(q)fc(q),且相应的压缩代码串为qp的时候(qp相邻,观察上图可知),只有在q被text(q)代替的情况下,代码q在字典中才不会有对应的文本,而这个文本应该是text(q)fc(q)。比如上面的q=3 p=7且原始文本段aab aaba,即text(7)=text(3)fc(3);又如q=4 p=5且原始文本段bb bbb,即text(5)=text(4)fc(4);而q=5 p=3的原始文本段为bbb aab,但是没有text(3)=text(5)fc(5)=bbbb这种情况。这是在编码过程中决定的。
解码是根据读取的代码来构建一个与编码之前完全相同的字典并输出对应的文本,而且也一定会将所有的代码读取完。
以上例子只展示了一个字符串只有a、b两个字符,以及初始字典为<a,0>、<b,1>,一般来说,常见文本文件是ASCII文件,所以这时的初始字典大小可以是256,包含了扩展ASCII码。
Code
1 | |
1 | |
测试一个ASCII文件
又测试一个文件其最后压缩时生成的字典
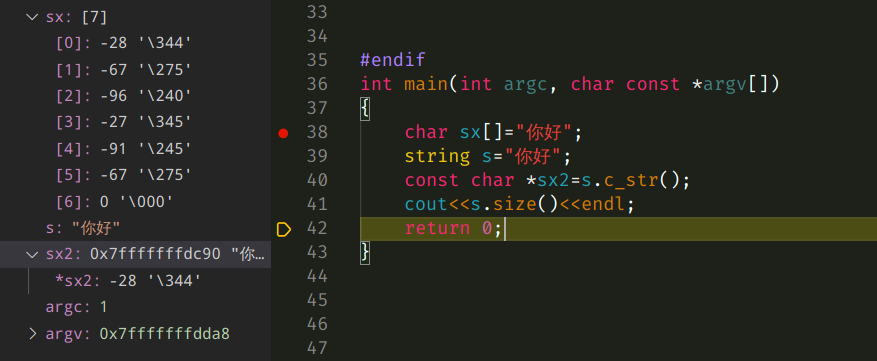
C++中char数组存储中文时,如果取其中一个char的话,由于char占用1个字节,使得中文发生截断(被分解),比如string s="你好"; 不过上面的测试依然可以通过,只要在编码过程中将被截断的所有char依次写入编码文件中,在解码时按照同样的规则去读取char,最后还是可以解码成功的。
就这样吧,等有空再来更新更新…
参考
《数据结构、算法与应用》
Lempel–Ziv–Welch
LZW压缩算法原理解析
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!